- linux 系统可以创建多少个进程
- 一个进程可以打开多少文件套接字
- 进程的状态
- 进程调度算法
- 进程的基本操作
- 进程通信(IPC)
linux 系统可以创建多少个进程
linux 系统可以创建的进程数可以通过ulimit -u查看
rxsi@VM-20-9-debian:~$ ulimit -u
15147
当然如果把这个数调大接近无限,也不代表就可以无限制的创建进程,因为每一个进程都需要有pid,因此也会受到系统pid上限的控制
rxsi@VM-20-9-debian:~$ cat /proc/sys/kernel/pid_max
32768
一个进程可以打开多少文件套接字
可以通过ulimit -n查看
rxsi@VM-20-9-debian:~$ ulimit -n
1024
使用lsof -p 进程号可以查看目标进程当前开启的套接字
rxsi@VM-20-9-debian:~/learncpp$ lsof -p 30165
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
blocking_ 30165 rxsi 0u CHR 136,2 0t0 5 /dev/pts/2
blocking_ 30165 rxsi 1u CHR 136,2 0t0 5 /dev/pts/2
blocking_ 30165 rxsi 2u CHR 136,2 0t0 5 /dev/pts/2
blocking_ 30165 rxsi 3u IPv4 2553317 0t0 TCP *:3000 (LISTEN)
进程的状态
进程总共有 7 种状态,我们可以通过top或ps指令进行查看,状态转换如下图所示:
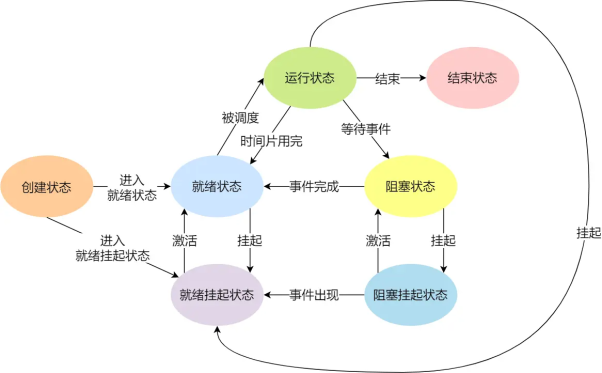
当进程处于挂起状态时将会被换出到磁盘,导致进程挂起的原因主要包括以下几点:(对应 top 指令显示的进程 T 状态)
- 通过 sleep 让进程间歇性挂起,其工作原理是设置一个定时器,到期后唤醒进程。
- 用户希望挂起一个程序的执行,比如在 Linux 中用 Ctrl+Z 挂起进程;
进程调度算法
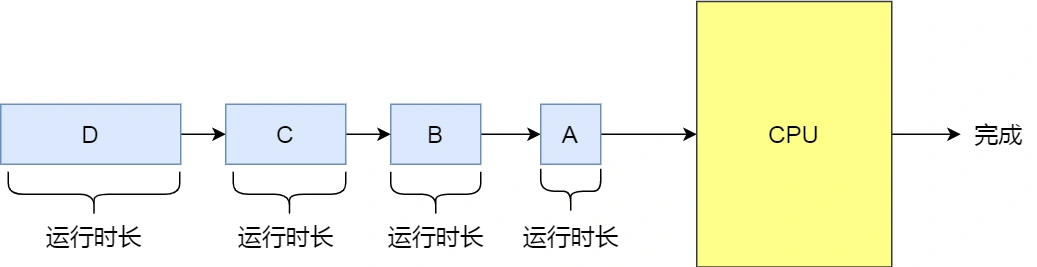
先来先服务调度算法
这是一种非抢占式的算法,当进程被创建放到就绪队列时,依照先后顺序排序,而当可以唤醒进程时则根据队列顺序依次唤醒进程,直到该进程退出或者被阻塞,才会选择下一个继续运行。这种方式的缺点是当有一个长作业的进程运行时,将会导致后面的短作业等待时间变长

最短作业优先调度算法
这种算法是一种抢占式的算法,是优先选择运行时间最短的进程来执行,因此有助于提升系统的吞吐量。这种方案的缺点是长作业进程获得运行的几率小
高响应比优先调度算法
这种算法也是一种抢占式的算法,权衡了短作业和长作业的运行,采用计算响应比优先级的方式:

- 等待时间相等时,短作业因为要求服务时间更短,因此优先级更高,获得运行的优先级更大
- 因为在同等时间下短作业具有更大的优先级,因此长作业往往会等待更长的时间,而随着时间的推进优先级会随等待时间增长而增加,因此长作业也可以获得运行机会
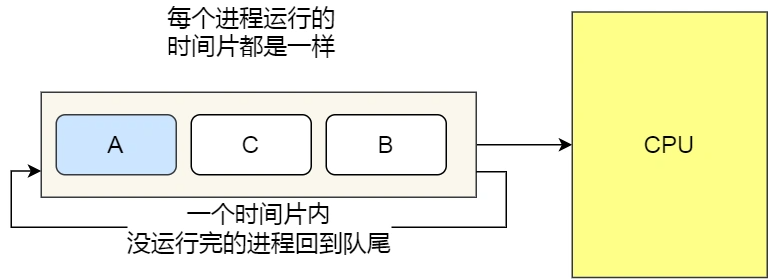
时间片转轮调用算法
这是一种非抢占式的算法,每个进程被分配了相等的时间片运行时间
- 如果时间片用完,则进行停止,并发生切换
- 如果进程在时间片用完之前就阻塞或者结束了,则发生切换(遇到阻塞就切换是非抢占式的)
最高优先级调度算法
这是一种抢占式的算法,这种算法是优先运行优先级高的进程,所以需要为每个进程设定优先级别,而优先级别也可以分为静态优先级和动态优先级。这种算法的缺点是会使低优先级获得运行的几率低
多级反馈队列调度算法
该算法是一种抢占式的算法,是时间片转轮算法和最高优先级算法的综合,同时兼顾了长短作业,同时也能保持较好的响应时间
- 多级:表示有多个队列,每个队列的优先级从高到低,同时优先级越高的时间片越短
- 反馈:表示如果有新的进程加入优先级高的队列时,立即停止当前正在运行的低优先级进程,转而先去运行高优先级的队列
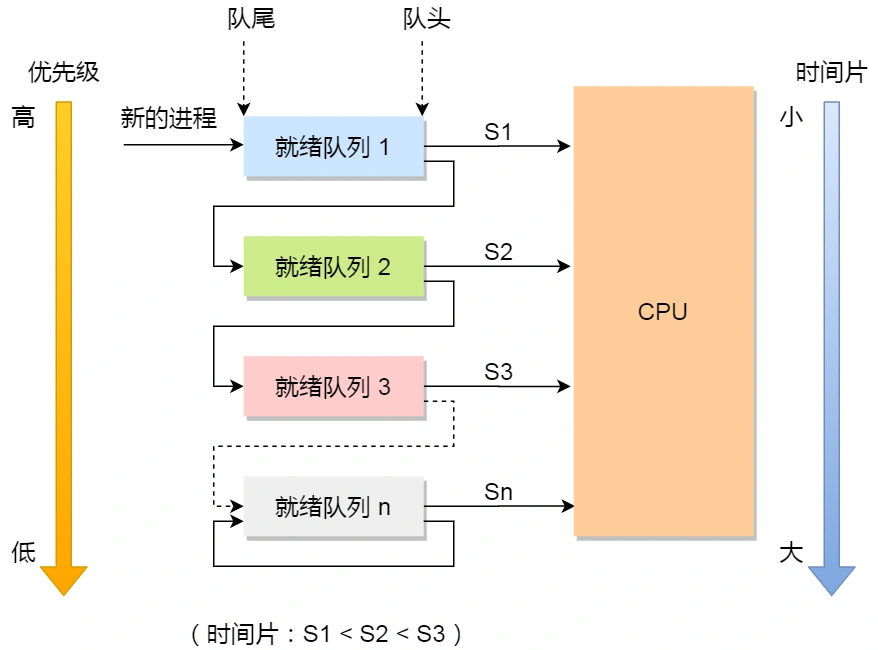
运行的方式是:
- 设置多个队列,队列的优先级从高到低,而时间片则是由短到长
- 新进程在被加入时,会首先放到第一级的就绪队列对位,然后按序运行。此队列的优先级最高,而时间片却最短,这样如果是短作业的进程则会立即运行完,而长作业如果没能成功运行完,则会放到下一级的队列。
- 当高优先级队列为空时,才会调用低优先级的队列的进程。如果低优先级队列在运行时,高优先级的队列有进程进入,则会立即中断,转而运行高优先级的进程。
进程的基本操作
system函数
system函数是为了启动一个新的进程以shell脚本的形式执行指令,等价于执行sh -c string。新的进程与原进程不共享数据,本质是先执行 fork 函数创建子进程再由子进程执行 exec 函数,并且父进程会使用 waitpid 等待子进程运行结束,因此这个过程是阻塞的。
函数签名
int system(const char* string);
// 示例
system("cd /home/rxsi/ && sh restart.sh");
资源影响
对于管道、FIFO、消息队列、共享内存等都不会被新进程继承和影响
exec函数族
exec函数主要用来替换当前进程,系统把代码段替换成新的程序的代码,废弃原有的数据段和堆栈段,重新从main函数开始重新执行,只保留pid、ppid和nice值,而生成新的代码段、数据段、堆栈段。对于系统而言,因为进程的 pid 没有变化,因此仍是原来的进程,但是程序代码已经完成替换。
函数签名
int execl(const char* path, const char* args, ...) // 函数说明:执行path字符串所代表的的文件路径,后面的参数是文件执行时的参数,并且最后要传入一个空指针作为结束
// 示例
execl("/bin/ls", "ls", "-al", "/etc/passwd", (char*)0);
资源影响
对于已经打开的管道和 FIFO、套接字,将会继续打开,除非这些文件设置了 FD_CLOEXEC 位,这个标志位的意思是在执行了exec族函数之后,该文件描述符会自动关闭,通常来说我们都是先 fork 出子进程再在子进程上执行 exec,因此此时新进程的套接字就成功被关闭了;对于 System V 消息队列没有任何影响,而 Posix 消息队列则会被关闭;对于锁则如果该锁具有进程间共享属性将会继续存在,否则消失;对于共享内存(mmap 共享内存、Posix 共享内存、System V 共享内存)都会去除映射。
fork函数
当一个进程调用fork函数之后,会向系统内核申请一个新的pid,然后创建新的task_struct结构,并对父进程的task_struct数据进行拷贝,对于虚拟空间内容则是通过写时拷贝技术进行高效的复制,最后将parent字段指向父进程的task_struct结构,子进程创建完毕
函数签名
#include <unistd.h>
pid_t id = fork();
fork函数没有参数,会返回一个pid_t参数用来表示子进程的PID号。如果返回的 pid 是0,则表示当前进程是子进程。如果 pid 大于0,则表示当前进程是父进程,这个pid就是子进程的pid。如果返回-1,则表明创建子进程失败,错误信息会在errno中。
fork出错有两种可能性:
-
当前进程数已经达到系统上限,此时
errno = EAGAIN,可以通过ps -aux | wc -l指令统计进程数 -
系统内存不足,此时
errno = ENOMEM,该情况与overcommit_memory参数相关,这个参数是控制是否允许当前系统所有进程的虚拟内存总数超过实际可用的物理内存。默认情况下,为了保守起见,该值为 0。但是在大部分情况下,比如某个进程 malloc() 了 200MB 内存,但是实际当前只使用到了 100MB 内存(内存页置换技术,物理内存页的分配只发生在使用的瞬间而非申请的瞬间),则有 100MB 的内存闲置了。当将该参数设置为 1,则只要程序申请,则系统就会进行内存的分配,当然如果发生了 OOM 问题,则会导致随机杀死进程,有一定的风险。可选值有:
- 0:默认值,允许单次分配不超过当前剩余物理内存 + swap 分区的内存,比如当前物理内存 + swap = 16G,此时不能一次性分配 17G,但是却可以多次分配 14G,这意味着实际总分配的虚拟内存是会超过物理内存 + swap 分区的,如果 OOM 那么系统随机杀死进程;
- 1:允许分配任意量级的内存,比如当前物理 + swap = 16G,那么单次分配 40G 都可以,在这种策略下,如果真的发生 OOM,那么系统会随机杀死进程;
- 2:不允许超量分配内存,当申请的内存 >= swap + 物理内存 * N,则拒绝本次内存申请。N 是个百分比,由 overcommit_ratio/100 确定
rxsi@VM-20-9-debian:~$ cat /proc/sys/vm/overcommit_ratio 50所以如果使用了 2 选项,那么就可能出现要申请大内存,比如一次性申请 4GB 内存,且明明内存空间还足够(使用
free命令可查当前内存空间使用情况),却无法分配内存的情况
资源影响
对于已经打开的管道和 FIFO,子进程将会获得父进程的副本;对于 System V 消息队列没有任何影响,而 Posix 消息队列(消息队列描述符实际就是普通的文件描述符)会获得父进程的副本;对于共享内存(mmap共享内存、Posix共享内存、System V共享内存)会继承和保留映射关系。
子进程会继承父进程开启的文件描述符(打开的文件、管道文件、套接字等都是文件描述符),如果创建子进程的目的是使用exec生成新的进程,那么可以给文件描述设置FD_CLOEXEC标记,这样当子进程执行exec族的函数时,该文件描述符将会自动关闭(Posix 消息队列默认会添加 FD_CLOEXEC 属性),方式如下:
fcntl (desc, F_SETFD, FD_CLOEXEC);
对文件锁的继承问题见:多进程/线程读写文件问题
进程关系
进程的亲缘关系开始于一个登陆 shell(称为一个会话)以及由该 shell 派生出的所有进程
父子进程
主进程通过fork函数创建的进程称为子进程,在子进程的task_struct中的struct task_struct __rcu* parent字段指向父进程
兄弟进程
由同个主进程通过fork函数创建的子进程称为兄弟进程,兄弟进程的struct task_struct __rcu* parent字段指向同个父进程
pid为1的进程
在 linux 系统启动时会有一个pid = 1的根进程,是所有进程的跟进程。当一个子进程的父进程退出时,子进程的ppid会指向该根进程
孤儿进程
当父进程在子进程退出前退出了,那么子进程会变为孤儿进程,子进程的ppid = 1,指向init进程。孤儿进程的释放由init进程管理,init进程会对其下每个进程退出后都调用wait函数,因此孤儿进程不会有系统危害。
僵尸进程
当父进程没有等待wait/waitpid等待,而子进程结束退出时,子进程称为僵尸进程。每个进程退出时,内核会释放相应的资源,但是仍会保留一定的信息,包括进程号、退出状态等,直到父进程调用wait/waitpid才会释放掉。当子进程成为了僵尸进程,那么该残留数据将不会得到释放,而系统能使用的进程号有限,因此僵尸进程会造成系统危害。
写时复制
在未有写时复制之前的 fork 函数,在复制进程空间时,总是把除了正文段以外的内存空间都复制一份,这实际上效率不高。正文段因为存储的是二进制可执行代码,因此对于父子进程来说是一致的,不需要额外在物理空间进行复制。
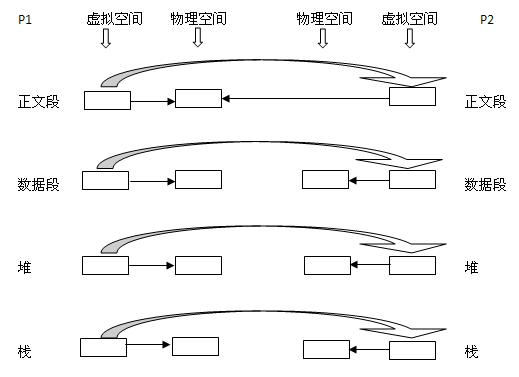
写时复制则只为子进程创建虚拟空间,而虚拟空间指向的物理空间则是和父进程一致。只有当父子进程中有更改相应内存段的行为才会分配新的物理空间。
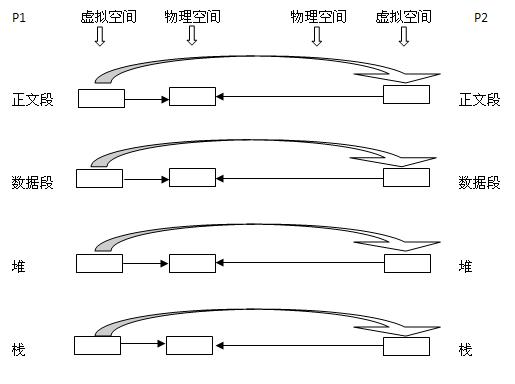
vfork函数则不为子进程创建虚拟空间,直接共享父进程的虚拟空间
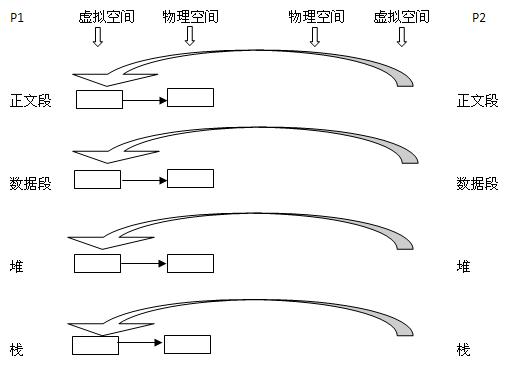
vfork创建新进程的目的在于先以最小成本创建一个子进程然后再用exec函数执行另外的程序。在子进程调用exec或exit之前子进程是和父进程共享同一个虚拟地址空间,而此时父进程是会被挂起(会被换到外存)。当子进程执行exec时,系统会把当前子进程的代码段替换为新的,然后会生成新的代码段、数据段、堆栈段等,但是 pid、ppid 不会改变,之后父进程就可以继续运行了。
clone函数可以指定创建进程的参数,可以自由选择继承父进程的哪些资源,甚至可以使创建出来的进程和原进程构成兄弟关系,而不是父子关系。通过指定共享当前进程的内存空间和文件等,实际就是生成了一个线程(注意:linux 并没有线程/进程的概念,只有任务(task_struct))
getpid函数
返回的是当前进程的 pid
pid_t getpid();
getppid函数
返回的是当前进程的父进程的 pid
pid_t getppid();
进程通信(IPC)
根据起源可以分为以下几类:
- 传统 Unix 进程通信方式
- 管道(pipe)
- 有名管道(fifo)
- 信号(signal)
- SystemV IPC对象:以整型 id 作标识
- 共享内存(share memory)
- 消息队列(message queue):支持指定优先级接收,不支持epoll等,
- 信号量(semaphore)
- BSD
- 套接字(socket)
- Posix IPC 对象:以 /somename 形式的字符作标识生成标识文件,需要unlink,因此进程宕机会造成残留标识文件
- 共享内存(share memory)
- 消息队列(message queue):支持mq_notify,支持epoll等,
- 信号量(semaphore)
管道(Pipe)与有名管道(FIFO)(随进程)
管道和有名管道在内核区的底层实现是一致的,只不过相较于 Pipe,FIFO 会在文件系统申请一个特殊的管道文件。
管道和有名管道的生命周期都是随进程,虽然管道和有名管道的数据是由内核维护,但是当最后一个打开管道/有名管道的进程关闭后,内核会把所有数据丢弃并删除该管道/有名管道(如果管道有数据未读出,则数据丢失)
优缺点
- Pipe 只能应用在有亲缘关系的进程,而 FIFO 可以应用于任意进程之间的通信
- 虽然 FIFO 在文件系统有对应的管道文件,但是在数据 IO 方面只与底层内核相关,不与磁盘相关,管道文件仅作标识用
- 内核的缓冲区有大小限制,默认为
/proc/sys/fs/pipe-max-size(1MB) - 当写入数据小于
PIPE_BUF(4096B)时,保证本次写入的原子性,这意味着如果是多进程同时写入多于PIPE_BUF的属性,需要加锁 - 内核缓冲区传输的是字节流
函数原型
// 管道
int fd[2];
int ret = pipe(fd);
// FIFO
int mkfifo(const char* pathname, mod_t mode);
int mknode(const char* pathname, mode_t mode | S_IFIFO, (dev_t)0);
// pathname是一个普通的Unix路径名,也是该FIFO的名字
// mode参数指定了文件权限和将被创建的文件类型(在此情况下是S_IFIFO),dev是创建设备特殊文件时使用的一个值,对于先进先出文件该值为0
当创建一个 FIFO 后,他必须以只读方式打开或者只写方式打开,FIFO 是半双工形式,一般的IO函数,如read、 write、close、 unlink都可以应用于FIFO。
管道在所有进程最终关闭之后自动消失,或者主动调用 close 函数。而文件系统中的 FIFO 文件则需要通过调用 unlink 函数进行删除,否则下次调用 mkfifo 会报错。管道文件是 p 类型文件:
rxsi@VM-20-9-debian:/tmp$ ls -al my_fifo
prwxr-x--- 1 rxsi rxsi 0 Oct 12 19:16 my_fifo
read/write
内核的管道缓冲区通过引用计数的方式记录了当前开启占用该管道的数量,在不同的情境下有不同的结果,且默认的模式都是阻塞模式,可通过fcntl函数设置非阻塞模式
// 对于管道来说,只能是通过该种方式
int flag;
flag = fcntl(fd, F_GETFL, 0); // 先获取原始属性
flag |= O_NONBLOCK; // 再原始属性的基础上加上非阻塞属性
fcntl(fd, F_SETFL, flag); // 设置新属性
// 对于FIFO来说,可以在调用open时指定
writefd = open(FIFO1, O_WRONLY | O_NONBLOK, 0);
- 当管道写端引用计数为0,当读端将缓冲区数据全部读出之后,再次读取会返回0
- 当管道读端引用计数为0,当写端调用
write函数时会收到SIGPIPE信号,进程接收到信号后会终止 - 当管道写端引用计数不为0,缓冲区数据为空,
read函数会阻塞至有管道数据 - 当管道读端引用计数不为0,
write函数在阻塞和非阻塞模式下有不同的表现:- O_BLOCK 模式且写入数据 n <= PIPE_BUF:如果缓冲区剩余空间足够,则立即写入且保证原子性,否则发生阻塞
- O_NONBLOCK 模式且写入数据n <= PIPE_BUF:如果缓冲区剩余空间足够,则立即写入且保证原子性,否则写入失败,
errno = EAGAIN,上层应该使用 loop 循环判断 - O_BLOCK 模式且写入数据 n > PIPE_BUF:
write函数会阻塞直到缓冲区有足够空间写入数据,但是不保证原子性 - O_NONBLOCK 模式且写入数据 n > PIPE_BUF:如果缓冲区已满,则返回失败,
errno = EAGAIN;如果有空余的写入空间,则写入相应大小的数据,write返回写入成功的数据,上层应用要监听该返回值,以判断是否全部写入完成
底层实现原理
当打开一个文件时,系统会为该文件在内核创建一个struct file结构,有多少个进程打开同一个文件,就会创建多少个file结构。file结构存储的是底层文件的信息,以及当前文件的偏移量,平时使用的fd,指向的底层结构就是file结构,当进程fork出子进程时,则子进程拷贝出的fd指向的是同一个fd结构,这也就实现了父子进程共享文件句柄。
而在file结构中有一个字段是f_inode,这个字段指向了VFS虚拟文件系统的inode结构,这个inode结构和实际文件中的inode不是同一个。之所以进行了一层抽象,是因为底层文件系统的类型有多样,比如ext4、ntfs等,所以使用VFS进行统一管理,使上层能够使用统一的接口进行文件系统的操作,而虚拟的inode管道的实现就借助了file结构和VFS虚拟文件系统的inode结构。
当进程开启管道,会同时创建两个file结构,分别对应写端和读端,这也就是为何我们使用int fd[2]; pipie(fd);了。这两个file结构指向了同一个inode,而inode又指向了物理数据页在内存中的缓存,因此管道实际的操作发生在内存。
示例代码
匿名管道:
// 管道
#include <stdio.h>
#include <unistd.h>
#include <string.h> // .h是C语言的头文件,没有.h是C++的头文件
#include <errno.h>
#include <sys/wait.h>
int main()
{
int fd[2];
int ret = pipe(fd);
if (ret == -1)
{
perror("pipe error\n"); // 将保存输出到标准错误输出stderr中.0是标准输入,1是标准输出,3是标准错误输出
return 1;
}
pid_t id = fork(); // fork之后,如果是0则代表是当前是子进程,但是在父进程中这个id是子进程的pid
if (id == 0)
{
int i = 0;
close(fd[0]); // 关闭读端
const char* child = "I am child ";
while (i < 10)
{
write(fd[1], child, strlen(child)+1);
sleep(1);
i++;
}
}
else if (id > 0)
{
close(fd[1]);
char msg[100];
int status = 0;
int j = 0;
while (j < 5) // 这里只读取5个数据后就关闭读端
{
memset(msg, '\0', sizeof(msg)); // 用以给指定内存块填充数据
ssize_t s = read(fd[0], msg, sizeof(msg));// 这个是有符号的整型,size_t是无符号的整型。size_t一般用来表示"适用于计量neiucn中可容纳的数据项目个数的无符号整数类型",因此通常用在数组下标和内存管理函数之类的函数;ssize_t一般用来表示"可以被执行读写操作的数据块的大小"
printf("%s %d\n", msg, j);
j++;
}
close(fd[0]);
pid_t ret = waitpid(id, &status, 0);// pid waitpid(pid_t pid, int* status, int options)
// 暂停当前进程的执行,等待有信号来到或者子进程结束,如果没有这行,那么子进程还没有运行结束,父进程就退出了
// 子进程的状态会存储在status中,如果只是当存想到阻塞功能,那么直接传入NULL即可
// pid < -1: 等待进程组识别码为pid绝对值的任何子进程
// pid = -1: 等待任何子进程,相当于wait()
// pid = 0: 等待进程组识别码与目前进程相同的任何子进程
// pid > 0: 等待任何子进程识别码为pid的子进程
// wait是阻塞版本
printf("exitsingle(%d), exit(%d)\n", status&0xff, (status>>8)&0xff);
// 输出为13, 通过 kill -l 可以知道是 SIGPIPE 信号。因为读端关闭而写端还在写入,因此抛出异常
}
else
{
perror("fork error\n");
return 2;
}
return 0;
}
有名管道:
// FIFO有名管道
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <errno.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define PATH "/tmp/my_fifo"
int main()
{
int ret = mkfifo(PATH, 0777); // 如果文件已经存在,那么会返回-1
if (ret == -1)
{
perror("pipe error\n");
return 1;
}
pid_t id = fork();
if (id == 0)
{
int fd = open(PATH, O_WRONLY);
int i = 0;
const char* child = "I am child by fifo";
while (i < 5)
{
write(fd, child, strlen(child)+1);
sleep(1);
i++;
}
close(fd);
}
else if (id > 0)
{
int fd = open(PATH, O_RDONLY);
char msg[100];
int status = 0;
int j = 0;
while (j < 5)
{
memset(msg, '\0', sizeof(msg));
ssize_t s = read(fd, msg, sizeof(msg));
printf("%s %d\n", msg, j);
j++;
}
close(fd); // 关闭管道文件
unlink(PATH); // 删除管道文件,底层使用了引用计数,即使这个语句放在open之后就调用,依然不会影响已经打开的FIFO管道.
// 如果放在open之前,则open函数会被阻塞
}
else
{
perror("fork error\n");
return 2;
}
return 0;
}
信号(随进程)
信号是 Linux 系统中用于进程之间通信或操作的一种机制,信号可以在任何时候发送给某一进程,而无须知道该进程的状态。如果该进程并未处于执行状态,则该信号就由内核保存起来,直到该进程恢复执行并传递给他为止。如果一个信号被进程设置为阻塞,则该信号的传递被延迟,直到其阻塞被取消时才被传递给进程。(D状态的进程不会处理kill信号)
信号是在软件层面对系统中断机制的一种模拟,是一种异步通信方式。但是和中断不同的是,中断的响应和处理都发生在内核空间,而信号的响应发生在内核空间,但是是在用户空间处理。内核不能直接杀死进程,只能向进程发出kill信号,然后由进程本身接收处理信号而结束自身
信号主要有两个来源:
- 硬件来源:用户按键出入
ctrl+c退出、硬件异常等 - 软件终止:调用了相关的系统函数:
kill、raise等
检测和响应信号的时机有两种情况:
- 当前进程由内核空间回到用户空间时
- 当前进程在内核中休眠而被唤醒时(这个唤醒可能是由于接收到了该信号,也可能是该信号不能唤醒该进程而等待进程自行被唤醒后再处理信号)
常见信号
使用kill -l可查看所有的信号
| 信号名 | 含义 | 默认操作 | 信号值 |
|---|---|---|---|
| SIGHUP | 在控制终端上发生的结束信号 | 终止 | 1 |
| SIGINT | 中断,用户键入Ctrl+C时发送 | 终止 | 2 |
| SIGQUIT | 终止,用户键入Ctrl+\时发送 | 终止并进行内核映像转储(dump core) | 3 |
| SIGILL | 非法指令 | 终止并进行内核映像转储(dump core) | 4 |
| SIGABRT | 有abort(3)发出的退出指令 | 终止并进行内核映像转储(dump core) | 6 |
| SIGFPE | 浮点异常,比如 3 / 0 | 终止并进行内核映像转储(dump core) | 8 |
| SIGKILL | 杀死进程,不能被阻塞、处理或忽略。D状态的进程不能被kill | 终止 | 9 |
| SIGSEGV | 无效的内存引用 | 终止并进行内核映像转储(dump core) | 11 |
| SIGPIPE | 向无人读管道写入数据 | 终止 | 13 |
| SIGALRM | 在一个定时器计时完成时发出,定时器可用进程调用alarm函数设置 | 终止 | 14 |
| SIGTERM | 终止信号 | 终止 | 15 |
| SIGCHILD | 子程序结束或停止时向父进程发出,如果父进程没有调用wait/waitpid等待该信号,则子进程会变成僵尸进程。 | 忽略 | 17 |
| SIGCONT | 让已暂停的进程继续运行 | 运行进程 | 18 |
| SIGSTOP | 停止信号,不能被阻塞、处理或忽略 | 停止进程 | 19 |
| SIGTSTP | 挂起信号,当用户按下挂起键Ctrl+Z时发送,这个信号是可以被处理的 | 停止进程 | 20 |
所以只有某些终止进程的信号才会使生成coredump文件,才可以进而使用gdb进行分析
信号的操作
| 函数 | 函数签名 | 功能 |
|---|---|---|
| kill | int kill(pid_t pid, int sig) | 发送信号给指定进程 |
| raise | int raise(int sig) | 发送信号给自身 |
| alarm | unsigned int alarm(unsigned int seconds) | 当定时时间到达后,向调用方发出SIGALRM信号 |
| pause | int pause(void) | 暂停进程,知道接收到任意信号 |
| signal | typedef void (*sighandler_t)(int); sighandler_t signal(int sig, sighander_t handler) |
捕捉信号,然后执行自定义的sighandler_t函数 |
示例代码
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <fcntl.h>
#include <errno.h>
#include <cstdlib>
int main()
{
pid_t pid;
int ret;
pid = fork();
int newret;
if (pid < 0)
{
perror("fork error\n");
exit(1);
}
else if (pid == 0)
{
raise(SIGSTOP); // 使子进程进入暂停状态
// sleep(5);
exit(0);
}
else
{
printf("child process pid = %d\n", pid);
if (waitpid(pid, NULL, WNOHANG) == 0) // 设置为WHOHANG时,只要子进程没有dead,则会返回0;可以使子进程暂停,也可以使子进程sleep(5)
{
if (ret = kill(pid, SIGKILL) == 0) // 杀死子进程
{
printf("kill child process");
}
else
{
perror("kill child process fail");
}
}
}
}
Posix消息队列(随内核、可设置回调)
消息队列相较于管道/FIFO的最大区别点在于,消息队列是面向消息块的,因此有明确的消息边界,各个消息块在内核中串联成一个队列。相较于 System V 消息队列,主要有以下几点差别:
- 对Posix消息队列的读总是返回最高优先级的最早消息,而System V消息队列在读取时可以指定返回某个优先级的消息
- 当往一个空队列放置消息时,Posix消息队列可以产生一个信号或者启动一个线程,而System V没有该机制
消息队列的声明周期是随内核的,因此进程退出后不会自动清除,需要手动调用关闭函数
mq_open函数
用以创建一个新的消息队列或者打开一个已存在的消息队列
#include <mqueue.h>
mqd_t mq_open(const char* __name, int __oflag, ...);
// 变参部分可能是 mode_t mode, struct mq_attr* attr 用以在当oflag含有O_CREAT时指定所要创建的消息队列的属性
// oflag参数可能是 O_RDONLY、O_WRONLY 、O_RDWR之一,也可能按位或 O_CREAT、O_EXCL、O_NONBLOCK
// 当调用成功时返回消息队列描述符(不同版本系统有不同的类型,出错则返回-1
mq_close函数
用以进程关闭消息队列,即声明调用进程不再使用该描述符,但是内核的消息队列不会从系统中删除。
等价于一个进程终止了,它所打开的所有消息队列会自动关闭,就像调用了mq_close一样
#inlucde <mqueue.h>
int mq_close(mqd_t mqdes);
// mqdes是通过mq_open打开的消息队列描述符
// 当调用成功时返回0,出错则返回-1
mq_unlink函数
当需要系统内核删除消息队列时,需要调用该函数
#include <mqueue.h>
int mq_unlink(const char* name);
// name参数是在mq_open中指定的文件系统路径
// 成功返回0,失败返回-1
当调用该函数,而还有进程持有该消息队列时,虽然 name 会被删除,但是直到最后一个进程 close 了该消息队列后,该队列才会真正的析构。(引用计数机制)
mq_getattr 和 mq_setattr函数
每个消息队列有四个属性,调用 mq_open 函数可以指定mq_maxmsg和mq_msgsize参数,调用 mq_setattr 函数可以指定mq_flags参数。(其他不能修改的参数会在对应函数中被忽略)
#include <mqueue.h>
int mq_getattr(mqd_t mqdes, struct mq_attr* attr);
int mq_setattr(mqd_t mqdes, const struct mq_attr* attr, struct mq_attr* oattr);
// mqdes:在使用mq_open函数创建的消息队列标识符
// struct mq_attr* attr:消息队列属性结构体
// 消息队列的四个属性
struct mq_attr
{
long mq_flags; // 消息队列标识,0 或者 O_NONBLOCK
long mq_maxmsg; // 消息队列能够存放的最大消息数量
long mq_msgsize; // 单个消息的最大字节数
long mq_curmsgs; // 当前消息队列的消息数
};
mq_send 和 mq_receive函数
用以往一个队列放入消息和取出消息,每个消息有有自己的优先级,mq_receive总是返回所制定队列中最高优先级的最早消息,System V消息队列可以任意指定优先级
#include <mqueue.h>
int mq_send(mqd_t mqdes, const char* ptr, size_t len, unsigned int prio);
// prio是插入消息队列的优先级,如果不需要使用优先级这个功能,那么传入0即可,无符号整数
// 成功返回0,失败返回-1
ssize_t mq_receive(mqd_t mqdes, char* ptr, size_t len, unsigned int *priop);
// priop是一个非空指针,因为获取的将是最高优先级的消息,因此当调用成功后,该指针将会被置为对应消息的优先级。当消息队列中的消息优先级都是0,那么只使用空指针即可
// 成功返回消息中的字节数,出错返回-1
mq_receive 函数的 len 参数不能小于 mq_attr 结构体中的 mq_msgsize 参数,如果小于该值,那么会立即返回 EMSGSIZE 错误,这意味着后面调用该函数时需要使用 mq_getattr 函数获取 size 参数。
mq_notify函数(重点区别)
用以实现异步事件通知,告知何时有一个消息放置到了某个空的消息队列中。
这是区别于System V消息队列的一个重要特性,如果没有异步事件通知,那么要么采用阻塞的形式调用 recv 函数,要么采用非阻塞+轮询的方式,这都造成了一定的CPU资源浪费。
#include <mqueue.h>
int mq_notify(mqd_t mqdes, const struct isgevent* notification);
union sigval
{
int sival_int;
void* sival_ptr;
};
struct sigevent
{
int sigev_notify; // SIGEV_(NONE, SIGNAL, THREAD) 三者之一
int sigev_signo; // 指定信号值
union sigval sigev_value; // 传递给线程的参数
void (*sigev_notify_function) (union sigval); // 线程的调用函数
pthread_attr_t *sigev_notify_attributes; // 线程属性
};
// 成功返回0,出错返回-1
从上面 sigevent 的定义可以看出,有两种通知方式:
- 产生一个信号,signal 机制
- 创建一个线程执行指定的函数
当进程调用 mq_notify 函数,且传入非空的 isgevent 结构体参数,那么意味着本进程要注册接收该队列的通知,如果 isgevent 结构体参数为空指针,那么代表着注销监听。
一个消息队列只能同时被一个进程监听,且如果消息到来时有另外的进程调用 mq_receive 函数阻塞等待消息,那么 mq_receive 函数会优先被唤醒。
每当进程接收到消息后,注册就会被撤销,因此每次需要重新注册。但是要在读出消息之前进行注册,否则在重新注册的过程中如果有信号产生,那么就会错失掉该信号!!!!!!!
消息队列的限制
- mq_maxmsg:队列中的最大消息数,通过mq_open函数指定
- mq_msgsize:消息体的最大字节数,通过mq_open函数指定
- MQ_OPEN_MAX:一个进程能够同时拥有的打开着的消息队列的数量
- MQ_PRIO_MAX:消息最大优先级+1(至少为32)
在 linux 系统中,Posix 消息队列的 mq_open 返回的消息队列描述符本质上就是一个通用的文件描述符,因此是可以直接应用在 select/poll/epoll 中的,同时我们也可以借助管道实现通用的设计。我们可以将向管道写入消息封装为一个回调函数,并注册在消息队列中,这样当消息队列接收到消息时,就会往管道写入消息,进而触发select/epoll事件。
示例代码
#include <stdio.h>
#include <mqueue.h>
#include <sys/stat.h>
#include <stdlib.h>
#include <unistd.h>
#include <algorithm>
#define PATH "/tmp" // 必须以/开头且只能含有一个/ 如果想要指定诸如 /tmp/my_mq 这种格式,则需要使用 mount 挂载路径
int main()
{
mqd_t msgid;
int text_size = 50;
msgid = mq_open(PATH, O_RDWR | O_CREAT, S_IRWXU | S_IRWXG, NULL); // 创建消息队列
if (msgid == (mqd_t)-1)
{
perror("mq_open error");
exit(1);
}
mq_attr msg_attr;
if (mq_getattr(msgid, &msg_attr) == -1) // 获取消息队列属性
{
perror("mq_getattr error");
exit(1);
}
pid_t pid = fork();
if (pid < 0)
{
printf("fork error");
exit(0); // exit(0)是正常退出程序,exit(1)是非正常退出程序.exit的退出会直接删除进程,并将信号返回到OS
}
if (pid == 0)
{
for (int i = 1; i < 10; ++i)
{
sleep(1);
char text[text_size] = "write msg from child process!" ;
if (mq_send(msgid, (char*)&text, text_size, i) == -1)
{
perror("mq_send error");
exit(1);
}
}
}
else
{
int size = std::max(text_size, (int)msg_attr.mq_msgsize);
printf("size = %d\n", size); // 默认是8192
for (int i = 1; i < 10; ++i)
{
char buf[text_size];
unsigned int priop; // 存放优先级的指针
if (mq_receive(msgid, (char*)&buf, size, &priop) == -1)
{
perror("mq_receive error");
exit(1);
}
printf("get the msg: %s, priority: %d\n", buf, priop);
}
if (mq_close(msgid) == -1)
{
perror("mq_close error");
exit(1);
}
if (mq_unlink(PATH) == -1)
{
perror("mq_unlink error");
exit(1);
}
}
return 0;
}
IPC对象
IPC 对象是内核级别的一种进程通信工具,通过标识符进行引用和访问,IPC 对象可以是 System V 消息队列、System V 共享内存、System V 信号量中的任一类型。
由以下结构体表示:
struct ipc_perm
{
key_t __key; // 通过ftok函数或者指定为IPC_PRIVATE而由内核自动分配一个唯一的ID
uid_t uid; // 拥有者的id,可通过IPC_SET修改
gid_t gid; // 拥有者的组id,可通过IPC_SET修改
uid_t cuid; // 创建者的id
gid_t cgid; // 拥有者的组id
unsigned short mode; // 权限,可通过IPC_SET修改
// mode可选有:
// 0400 用户有读权限
// 0200 用户有写权限
// 0040 与用户同组的用户都有读权限
// 0020 与用户同组的用户都有写权限
// 0004 其他用户有读权限
// 0002 其他用户有写权限
// 如果设置0666,则代表所有用户都有可读可写权限,例如通过msgget(key_t key, 0666|IPC_CREATE)的方式创建并设置权限
unsigned short __seq; // 序列号
};
当尝试访问 IPC 对象时,IPC 会执行两级检查:
- 检查调用者的
oflag参数有没有在该对象 ipc_perm 结构 mode 成员中的任何访问位 - 检查用户是否有访问权限(uid、gid、cuid、cgid)
ftok函数
用以创建 IPC 对象标识符,该对象类型是 key_t(32位整数)
#include <sys/ipc.h>
key_t ftok(const char *pathname, int proj_id);
// const char* pathname:用以产生key_t值的文件路径,该路径必须存在,如果不存在,那么会返回-1
// int proj_id:自定义的子序号,虽然是int类型,但是实际计算时只会使用后8bit
当函数执行时,会根据文件路径所在的文件系统的信息(stat结构的st_dev成员)和该文件在文本系统内的索引节点号(stat结构的st_ino成员),结合 proj_id 进行计算,具体计算逻辑是:proj_id后8位 + st_dev的后8位 + st_ino的后16位,组成共32位的值。但是要注意的是,只有保证指定的文件路径不被删除,通过 ftok() 计算得出的值才是固定值。否则如果先对文件进行删除之后再创建同名文件,因为文件inode信息可能已经改变,因此计算出的结果不相同
ftok 只是需要根据文件路径去获取文件信息,因此要求文件必须存在,且是可访问的
ipcs 指令 和 ipcrm 指令
由于System V IPC的三种类型不是以文件系统中的路径名标识,因此使用标准的ls和rm程序无法看到和删除它们。因此提供了ipcs用以查看,ipcrm用以删除
- ipcs:显示当前系统创建的ipc对象
rxsi@VM-20-9-debian:~$ ipcs ------ Message Queues -------- key msqid owner perms used-bytes messages ------ Shared Memory Segments -------- key shmid owner perms bytes nattch status 0x00005feb 0 root 666 12000 1 ------ Semaphore Arrays -------- key semid owner perms nsems - ipcs -l:显示ipc系统内核限制
rxsi@VM-20-9-debian:~$ ipcs -l ------ Messages Limits -------- max queues system wide = 32000 max size of message (bytes) = 8192 default max size of queue (bytes) = 16384 ------ Shared Memory Limits -------- max number of segments = 4096 max seg size (kbytes) = 18014398509465599 max total shared memory (kbytes) = 18014398509481980 min seg size (bytes) = 1 ------ Semaphore Limits -------- max number of arrays = 32000 max semaphores per array = 32000 max semaphores system wide = 1024000000 max ops per semop call = 500 semaphore max value = 32767 - ipcrm -M shmkey:用以移除用shmkey创建的共享内存段
- ipcrm -m shmid:用以移除用shmid标识的共享内存段
- ipcrm -S semkey:用以移除用semkey标识的信号量
- ipcrm -s semid:用以移除用semid标识的信号量
- ipcrm -Q msgkey:用以移除用msgkey标识的消息队列
- ipcrm -q msgid:用以移除用msgid标识的消息队列
消息队列(随内核、可指定接收优先级)
消息队列提供了一种从一个进程向另一个进程发送一个数据块的方法,消息队列是消息的链接表,存放在内核中并由消息队列标识符标识。每个消息数据块都含有一个类型,接收进程可以独立的接收含有不同类型的数据结构,且具有最大长度限制。
消息队列可以在没有接收进程的情况下发送消息给消息队列,避免了管道/FIFO的同步和阻塞问题(管道类型要求至少存在一个读端和写端),生命周期随内核。
队列的系统参数
rxsi@VM-20-9-debian:~$ ipcs -l
------ Messages Limits --------
max queues system wide = 32000
max size of message (bytes) = 8192
default max size of queue (bytes) = 16384
msgget函数
用以打开一个现存的队列或者创建一个消息队列
int msgget(key_t key, int msgflg);
// key_t: 本质是int类型
// msgflg: 表示的权限标识,表示消息队列的访问权限。
// msgflg可以与IPC_CREATE做 | 操作,表示当key所命名的消息队列不存在时,创建一个消息队列,如果key命名的消息队列存在,则IPC_CREATE会被忽略,则只返回一个标识符(非0);如果创建失败,则返回-1。
当成功创建了一个新的队列,那么会关联到一个结构体 msqid_ds ,通过该结构体可以控制消息队列的行为
struct msqid_ds
{
struct ipc_perm msg_perm; // 权限设置,类似文件访问权限
time_t msg_stime; // 最后调用msgsnd调用时间
time_t msg_rtime; // 最后调用msgrcv调用时间
time_t msg_ctime; // 队列的创建时间或者最后调用msgctl执行IPC_SET操作
unsigned long msg_cbytes; // 当前队列中所有消息的总长度
msgqnum_t msg_qnum; // 当前队列中有多少个消息
msglen_t msg_qbytes; // 当前队列能够存放的消息体的总字节大小
pid_t msg_lspid; // 最后调用msgsnd的进程的ID
pid_t msg_lrpid; // 最后调用msgrcv的进程的ID
};
msgctl函数
用以控制队列的权限和行为,如删除队列
int msgctl(int msqid, int cmd, struct msqid_ds* buf);
// msqid:在msgget创建的id
// cmd可选值:
// IPC_STAT: 将在msgget创建的key 和 msqid_ds结构体关联信息,复制到buf中.不过调用次方法的用户要有读权限
// IPC_SET:可设置某些属性
// IPC_RMID:删除消息队列,会唤醒所有的读进程和写进程,给这些进程返回errno=EIDRM,msgctl的buf参数可以设置为NULL
// 当调用成功会返回0,如果失败则返回-1,且errno会被设置为对应的状态
msgsnd 和 msgrcv
// 发送消息到消息队列,调用者需要有写权限
int msgsnd(int msqid, const void* msgp, size_t msgz, int msgflg);
// 从消息队列中取出消息,调用者需要有读权限
ssize_t msgrcv(int msqid, void* msgp, size_t msgsz, long msgtyp, int msgflg);
void* msgp 指向一个结构体,用以存放实际的消息数据,这个结构体名可以自定义,但是必须要含有long mtype和char mtext[xxx]这两个字段,这是 msg.h 中的规定
struct msgbuf
{
long mtype; // 消息类型,需要>0
char mtext[1]; // 消息体,该大小由size_t msgz指定
};
当已有插入消息的总字节数超过了msg_qbytes字段(这个字段定义在 msqid_ds 结构体中),或者总消息数量超过了该值(这是为了避免无限插入长度为0的消息),则插入失败返回-1
当读取消息时,如果 msgrcv 函数的msgsz参数小于所要接收的消息的 mtext 长度,则如果设置了 MSG_NOERROR 那么会截断该消息的 mtext 字段,并把新消息传入void* msgp所指向的结构体中,并移除原消息;否则读取失败返回-1,并且 errno = E2BIG,原消息不会被移除。
对于消息类型的读取,是通过 msgrcv 函数中的msgtyp参数控制:
- msgtype == 0:消息队列中的首个消息将被读取
- msgtyp > 0:消息队列中的 msgbuf 中与之相等的 mtype 的消息会被读取
- msgtyp < 0:消息队列中第一个小于等于该绝对值的消息会被读取(实现对一个范围的消息进行读取)
阻塞和非阻塞
如果消息队列空间不足,那么 msgsnd 会阻塞到空间足够。如果 msgsnd 函数的msgflg有设置 IPC_NOWAIT 参数,那么会立即返回失败,错误码 errno = EAGAIN 。当 msgsnd 为阻塞时,如果队列被移除(errno = EIDRM)或者被信号打断如(errno = EINTR),那么会返回失败-1。
当调用 msgrcv 函数时,如果消息队列中已经没有目标类型消息,如果msgflg没有设置 IPC_NOWAIT 参数时,读取操作将会进入阻塞,直到有目标消息类型的消息被放入消息队列中,或者该消息队列被移除。当读取成功时,msgrcv 函数返回对应的字节数,否则返回-1。如果处于非阻塞状态,则读取失败后的 errno = EAGAIN
示例代码
#include <sys/msg.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <string.h>
#include <iostream>
#define MAX_TEXT_SIZE 50
struct msg_buf
{
long mtype;
char mtext[MAX_TEXT_SIZE];
};
int main()
{
int msgid = msgget((size_t)123, 0666 | IPC_CREAT);
if (msgid == -1)
{
perror("msgget error");
return 1; // 通过return的方式是把栈弹出,回到上层调用,这里在main函数因此起到退出进程的效果
}
pid_t pid = fork();
if (pid < 0)
{
printf("fork error");
exit(0); // exit(0)是正常退出程序,exit(1)是非正常退出程序.exit的退出会直接删除进程,并将信号返回到OS
}
if (pid == 0)
{
for (int i = 1; i < 10; ++i)
{
msg_buf buf;
sleep(1);
char text[MAX_TEXT_SIZE] = "write msg from child process!" ;
buf.mtype = i; // 注意这里不能是0!!!!
strcpy(buf.mtext, text); // 注意这里不能是buf.mtext = text;
// 因为数组名在C语言中退化为常量指针,因此不能使用=号
// 只能使用memcpy(字符数组是strcpy),或者使用循环赋值的方式
if (msgsnd(msgid, &buf, MAX_TEXT_SIZE, 0) == -1)
{
perror("msgsnd failed");
exit(1);
}
}
}
else
{
msg_buf buf;
for (int i = 1; i < 10; ++i)
{
if (msgrcv(msgid, (void*)&buf, MAX_TEXT_SIZE, i, 0) == -1) // 这里设置i不为0,因此会接收对应的消息序号,如果是0,则每次都接收消息队列的头一个
{
perror("msgrcv fail");
exit(1);
}
printf("get the msg: %s\n", buf.mtext);
}
if (msgctl(msgid, IPC_RMID, 0) == -1)
{
perror("msgctl fail");
exit(1);
}
exit(0);
}
}
mmap共享内存(随内核、基于Page Cache,用来做高性能文件读写)
mmap 通过将文件(open+mmap)或者共享内存体(shm_open+mmp,Posix共享内存)映射到进程地址空间,主要有两方面的应用:
- 通过多个进程共享文件的映射进程地址空间,避免了每个进程都对文件进行拷贝,避免使用 read、write 等函数(会造成用户态和内核态切换,数据拷贝等),效率更高
- 因为该进程地址是所有进程共享的,因此可以实现进程间的数据通信
- 该内核映射空间就是
PageCache空间 - mmap 区的增长方向是从大到小,和栈的增长方向一致
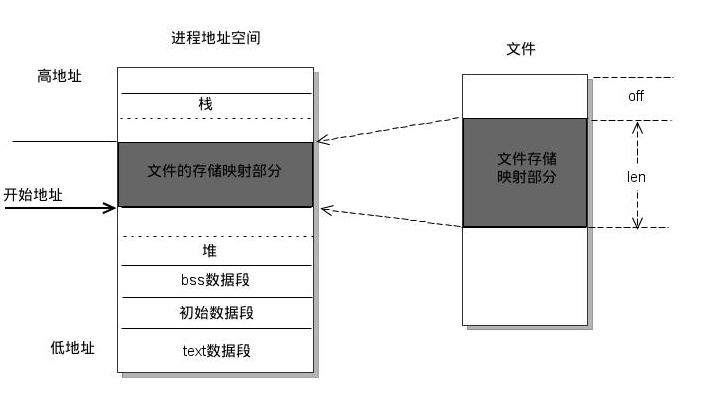
但是注意,并不是每个文件类型都可以使用 mmap,比如 访问终端fd、socket fd 就不可以使用 mmap 进行映射。
linux 内核使用 vm_area_struct 结构表示一个独立的虚拟内存区域,由于存在多种功能和内部机制不同的虚拟内存区域,因此一个进程使用多个 vm_area_struct 结构来表示不同类型的虚拟内存区域。各个 vm_area_struct 结构使用链表和红黑树结构链接,方便进程快速访问:
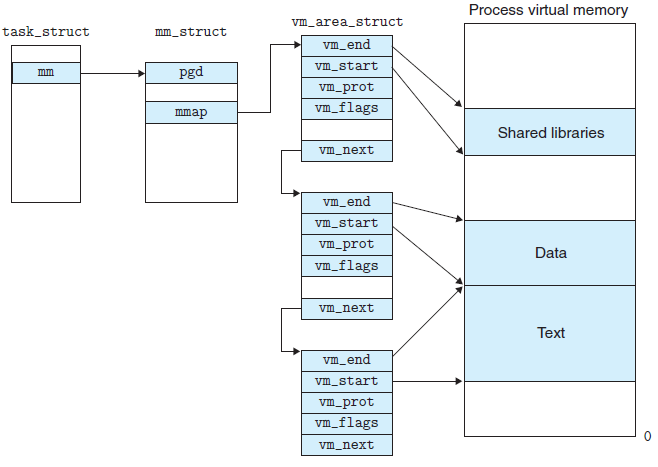
mmap 内存映射原理
-
进程启动映射过程,并在虚拟地址空间中为映射创建虚拟映射区域:(创建VMA)
当调用 mmap 函数时,传入的
size_t length一般是传入的文件的大小,该值不需要强制指定为页的整数倍大小,内核会自动向上调整。内核会根据该值寻找一段空闲的满足要求的连续虚拟地址,且为该虚拟地址分配一个 vm_area_struct 结构,接着对该结构进行初始化,最后将该虚拟结构插入进程的虚拟地址区域链表或树。 -
通过 mmap 函数实现文件物理地址和进程虚拟地址的映射关系:(VMA和文件形成映射)
在分配了新的虚拟地址区域之后,通过待映射的文件指针,在文件描述符表中找到对应的文件描述符,通过该文件描述符链接到内核的“已打开文件集”中该文件的文件结构体(struct file),建立文件地址和虚拟地址区域的映射关系。
-
进程发起对这片映射空间的访问,引发缺页异常,实现文件内容到物理内容的拷贝:(缺页异常)
当建立起映射关系后,并没有把文件数据拷贝到主存,而是当进程发起读或写操作时,引发出缺页异常,使内核请求调页过程。当进程对主存进行写操作修改了内容,一定时间之后系统会自动写回脏页到磁盘空间(可通过msync()进行强制同步)
mmap函数
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
/*
void* addr:用户进程中所要映射的用户空间的起始地址,通常为NULL(由内核指定,内核根据/proc/sys/vm/mmap_min_addr地址计算)
size_t length:要映射的内存区域的大小
int prot:期望的内存保护标志,不能与文件的打开模式冲突
- PORT_EXEC:页内容可以被执行
- PORT_READ:页内容可以被读取
- PORT_WRITE:页可以被写入
- PORT_NONE:页不可访问
int flags:指定映射对象的类型,映射选项和映射页是否可以共享
- MAP_FIXED:使用指定的映射起始地址,如果由start和len参数指定的内存区重叠于现存的映射空间,重叠部分将会被丢弃。如果指定的起始地址不可用,操作将会失败。并且起始地址必须落在页的边界上。
- MAP_SHARED:与其它所有映射这个对象的进程共享映射空间。对共享区的写入,相当于输出到文件。直到msync()或者munmap()被调用,文件实际上不会被更新。当设置该属性时,fork出的子进程将会继承该共享内存区域
- MAP_PRIVATE:建立一个写入时拷贝的私有映射。内存区域的写入不会影响到原文件。这个标志和以上标志是互斥的,只能使用其中一个。
int fd:有效的文件描述符
off_t offset:被映射对象内容的起点
return: 成功返回映射区的起始地址,出错则返回MAP_FAILED
*/
用以创建VMA并将某个文件映射到进程地址空间中,一般有三种类型方式:
- 使用普通文件以内存映射IO(open + mmap),一般是用来实现零拷贝
- 使用特殊文件提供匿名内存映射(使用 mmap 时指定flag=MAP_ANONYMOUS,fd=-1),一般用于亲缘关系的进程
- 使用 Posix 共享内存区(shm_open + mmap),一般用来作为进程通信
munmap函数
#include <sys/mman.h>
int munmap(void* addr, size_t len);
/*
void* addr:映射区的地址
size_t len:映射区的大小
return:成功返回0,出错返回-1
*/
用以从某个进程的地址空间删除一个映射关系,此时如果映射区是被MAP_PRIVATE标志映射的,那么调用进程对它所作的变动都会被丢弃掉。
msync函数
#include <sys/mman.h>
int msync(void* addr, size_t len, int flags);
/*
void* addr:映射区的地址
size_t len:映射区的大小
int flags:标志位
- MS_ASYNC:执行异步写
- MS_SYNC:执行同步写
- MS_INVALIDATE:使高速缓存的数据失效
return:成功返回0,出错返回-1
*/
当映射区被标记为MAP_SHARED,那么我们修改了处于内存映射区的文件内容,那么内核将会在稍后某个时刻写入到磁盘文件。我们可以使用 msync 函数立即执行写回操作。
示例代码
匿名共享,只适用于亲缘关系的进程:
#include <sys/mman.h>
#include <unistd.h>
#include <fcntl.h>
#include <semaphore.h>
#include <iostream>
#include <string.h>
#define PATH "/home/tmp/mmap_text.txt"
#define SEM_PATH "/tmp"
#define FILE_MODE (S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH)
int SIZE = 100;
int main()
{
char* ptr = (char*)mmap(NULL, SIZE, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, -1, 0); // 当指定了MAP_ANONYMOUS属性时,代表不需要使用file,因此fd填入-1即可,用在有亲缘关系的进程间的通信
pid_t pid = fork();
if (pid == 0)
{
char s[SIZE] = "child string";
memcpy(ptr, s, SIZE);
}
else if (pid > 0)
{
sleep(1); // 使子进程先写入
char* ret = new char[SIZE];
memcpy(ret, ptr, SIZE);
std::cout << ret << std::endl;
munmap(ptr, SIZE);
}
return 0;
}
基于普通文件的共享:
#include <sys/mman.h>
#include <unistd.h>
#include <fcntl.h>
#include <semaphore.h>
#include <iostream>
#include <string.h>
#include <sys/stat.h>
#define PATH "/tmp/mmap_text" // 注意该文件要存在,否则会报 Segmentation fault
#define FILE_MODE (S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH)
size_t getFileSize(const char* filename)
{
struct stat st;
stat(filename, &st);
return st.st_size;
}
int main()
{
int fd = open(PATH, O_RDWR); // 这里的模式要是RDWR,同时可读写
int fileSize = getFileSize(PATH); // 当使用open + mmap时,该大小要通过获取文件配置的方式获得,而shm_open + mmap可以自由指定大小
char* ptr = (char*)mmap(NULL, fileSize, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
pid_t pid = fork();
if (pid == 0)
{
char s[fileSize] = "child string";
memcpy(ptr, s, fileSize);
}
else if (pid > 0)
{
sleep(1); // 让子进程先写入
char* ret = new char[fileSize];
memcpy(ret, ptr, fileSize);
std::cout << ret << std::endl;
munmap(ptr, fileSize);
close(fd);
}
return 0;
}
Posix共享内存(随内核、生成的共享内存对象在tmpfs虚拟文件系统上,一般挂载路径为/dev/shm)
底层本质还是 mmap 共享内存机制,只不过是基于共享内存区对象实现的方式
shm_open函数
#include <sys/mman.h>
int shm_open(const char *name, int oflag, mode_t mode);
/*
const char *name:具体存在的系统路径,以/开头,且只能包含一个/
int oflag:至少要含有只读标志(O_RDONLY),亦或者同时含有读写(O_RDWR),同时可以包含O_CREATE、O_EXCL或O_TRUNC。如果指定了O_RDWR | O_TRUNC,则如果共享内存区对象已经存在,会截断至0长度
mode_t mode:权限位,在指定了O_CREAT标志下生效,如果非创建则填入0即可
return: 成功返回非负描述符,出错返回-1
*/
返回的描述符用以在mmap函数的 fd 参数处使用
shm_unlink函数
int shm_unlink(const char *name);
/*
const char *name:路径名
return: 成功返回0,失败返回-1
*/
用以删除一个共享内存区对象的名字,同样的也会在底层对象的引用计数为0后才真正删除
ftruncate函数
#include <unistd.h>
int ftruncate(int fd, off_t length);
/*
int fd:描述符
off_t length:目标长度
return:成功返回0,出错返回-1
*/
用以改变共享内存区的大小,针对普通文件和共享内存区对象有不同的处理方式:
- 普通文件:
- 文件的大小 > length参数:额外的数据会被丢弃
- 文件的大小 < length参数:扩展文件。但不是所有系统都保证可以实现,另一种实现的方式是使用
lseek偏移到length-1处,再使用write函数写入扩展长度的数据
- 共享内存对象:
- 会直接修改对应内存对象的大小
fstat函数
#include <sys/types.h>
#include <sys/stat.h>
int fstat(int fd, struct stat *buf);
/*
int fd:描述符
struct stat *buf:该结构体用以存储信息,比如文件的大小等
*/
用以获取当前文件描述符 fd 的信息
示例代码
#include <sys/mman.h>
#include <unistd.h>
#include <fcntl.h>
#include <semaphore.h>
#include <iostream>
#include <string.h>
#include <sys/stat.h>
// 编译:g++ IPC_test.cpp -o bin/IPC_test -lrt
#define PATH "/mmap_text" // 使用open+mmap是要求该文件一定存在,不计较包含了多少个/。
// 使用shm_open + mmap则一定只能包含一个/,因此"/tmp/mmap_text"是错误的,文件可不存在,这里只是作为标识,实际挂载在tmpfs虚拟文件系统,路径在/dev/shm
// 比如这里我们定义的是mmap_text,那么当运行之后就会生成/dev/shm/mmap_text文件
int SIZE = 100;
int main()
{
int fd = shm_open(PATH, O_RDWR | O_CREAT, S_IRUSR | S_IWUSR);
int res = ftruncate(fd, SIZE); // 默认创建之后的size是0,因此一定要先调用ftruncate调整大小
if (res == -1)
{
perror("ftruncate error");
exit(1);
}
char* ptr = (char*)mmap(NULL, SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
pid_t pid = fork();
if (pid == 0)
{
char s[SIZE] = "child string";
memcpy(ptr, s, SIZE);
}
else if (pid > 0)
{
sleep(1); // 让子进程先写入
char* ret = new char[SIZE];
memcpy(ret, ptr, SIZE);
std::cout << ret << std::endl;
munmap(ptr, SIZE);
close(fd);
shm_unlink(PATH);
}
return 0;
}
System V共享内存(随内核、基于tmpfs虚拟文件系统)
System V 共享内存的实现类似于 Posix 共享内存,对于每个共享内存区,内核会维护如下的数据结构:
#include <sys/shm.h>
struct shmid_ds
{
struct ipc_perm shm_perm; // 每个IPC对象的权限设置
size_t shm_segsz;
pid_t shm_lpid; // 最后操作该共享内存区的pid
pid_t shm_cpid; // 创建该共享内存区的pid
shmatt_t shm_nattch;
shmat_t shm_cnattch;
time_t shm_atime;
time_t shm_dtime;
time_t shm_ctime;
}
shmget函数
#include <sys/shm.h>
int shmget(key_t key, size_t size, int oflag);
/*
key_t key:通过ftok函数返回的标识符,也可以是IPC_PRIVATE(由内核自行分配唯一的标识符)
size_t size:以字节位单位,如果是创建新的共享内存区,则不为0,否则应该为0
int oflag:IPC_CREAT 或 IPC_CREAT | IPC_EXCL
return:成功返回共享内存区对象的id(shmid),出错返回-1
*/
用以创建或者打开一个已存在的共享内存区,注意调用该函数的进程并没有链接到该进程的地址空间
shmat函数
#include <sys/shm.h>
void *shmat(int shmid, const void *shmaddr, int flag);
/*
int shmid:由shmget返回的标识符
const void *shmaddr:指定的共享内存区地址,一般使用空指针即可,有系统自动选择,如果是非空指针,则由 flag 中的SHM_RND影响
int flag:限定权限
return:成功返回映射区的起始地址,出错返回-1
*/
用以将申请的共享内存区链接到调用进程的地址空间(堆空间和栈空间之间的中间区域,就是mmap共享内存区域)
shmdt函数
#include <sys/shm.h>
int shmdt(const void *shmaddr);
/*
const void *shmaddr:由shmat函数返回的共享内存区指针地址
return:成功返回0,出错返回-1
*/
当进程主动调用该函数时,将会断接这个内存区,当一个进程终止时,它当前所有链接的共享内存区都会自动断接
注意,本函数不会删除共享内存区
shmctl函数
#include <sys/shm.h>
int shmctl(int shmid, int cmd, struct shmid_ds *buff);
/*
int shmid:标识符
int cmd:命令类型:
- IPC_RMID:删除共享内存区
- IPC_SET:设置共享内存区对应的shmid_ds结构的三个成员:shm_perm.uid, shm_perm.gid, shm_perm.mode,这些值由buff参数提供
- IPC_STAT:将共享内存区当前的shmid_ds结构体属性设置到buff参数中
struct shmid_ds *buff:shmid_ds结构体
return:成功返回0,出错返回-1
*/
示例代码
#include <sys/shm.h>
#include <unistd.h>
#include <fcntl.h>
#include <semaphore.h>
#include <iostream>
#include <string.h>
#include <sys/stat.h>
// #define PATH "/tmp/system_v_shm" // 这里文件不要求只有一个/,但是要求有文件的权限,因此使用/tmp/system_v_shm需要使用sudo的方式运行
#define PATH "/home/rxsi/system_v_shm" // 这里可以
int SIZE = 100;
int main()
{
// 对应的文件路径必须要存在,后面的255实际只会用上后8位
// 因为实际只是通过该文件名获得到对应inode信息,因此文件必要存在且具有访问权限
key_t key = ftok(PATH, 255);
if (key == -1)
{
perror("ftok error");
exit(1);
}
// 以下三种形式都是借助了tmpfs虚拟文件系统,但是创建的文件是不可见的
// int shmid = shmget(key, SIZE, IPC_CREAT | SHM_R | SHM_W); // 1.通过 ftok 创建的ID
// int shmid = shmget(IPC_PRIVATE, SIZE, IPC_CREAT | SHM_R | SHM_W); //2. 可以使用IPC_PRIVATE由内核自行分配
int shmid = shmget(1234, SIZE, IPC_CREAT | SHM_R | SHM_W); // 3. 自定义序号
if (shmid == -1)
{
perror("shmget error");
exit(1);
}
pid_t pid = fork();
if (pid == 0)
{
struct shmid_ds buff;
char *ptr = (char*)shmat(shmid, nullptr, 0);
shmctl(shmid, IPC_STAT, &buff);
char s[SIZE] = "child string";
memcpy(ptr, s, SIZE);
int res = shmdt(ptr);
if (res == -1)
{
perror("shmdt error");
exit(1);
}
}
else if (pid > 0)
{
sleep(1); // 让子进程先写入
char *ptr = (char*)shmat(shmid, nullptr, 0);
char* ret = new char[SIZE];
memcpy(ret, ptr, SIZE);
std::cout << ret << std::endl;
int res = shmdt(ptr);
if (res == -1)
{
perror("shmdt error");
exit(1);
}
res = shmctl(shmid, IPC_RMID, nullptr);
if (res == -1)
{
perror("shmctl error");
exit(1);
}
}
return 0;
}