分布式系统的设计
要建立分布式系统,一般有两个思考方向:
- 所有节点的数据都一致,这需要应用共识性算法,如 raft、paxos 等
- 节点数据不一致,以
哈希取余的方式计算当前数据的落点,即每个节点只保存有一部分的数据
单纯使用hash算法的弊端在于,它需要向当前节点数进行取余操作,这就导致了如果节点数量发生扩容或者缩容,则计算出的数据落点会不一样,因此需要进行洗数据。
不过如果节点只是作为缓存用,即只用作数据读取而对数据的修改会直接写回后端数据库等具有持久化的服务进行落地,那么扩容/缩容后的真实数据是可以从持久化服务进行恢复的,在扩容或者缩容之后对原数据的恢复倒不是什么大问题。比方说原有的缓存系统有三个缓存节点,那么现在扩容到四个节点,假设之前有份数据的缓存落点是在节点三,而扩容后落点是在节点四。那么在读取时由于节点四没有该份数据,因此会直接从后端的数据库加载并存入到节点四,而节点三原有的旧数据则可以依赖于缓存过期的自动删除,再者就算没有设计删除过期缓存的功能,这些脏数据也顶多只是占用内存,不会再被访问到。当然如果在旧数据过期之前又进行了一次扩容/缩容,那么就有可能会使读取到过期的脏数据,造成异常,所以对缓存设计过期时间是有很大的必要性的。
如果节点是作为数据存储节点使用,那么上面提到的hash算法的问题就会有影响了,每次扩容或者缩容时都需要进行大规模的数据迁移。
一致性hash
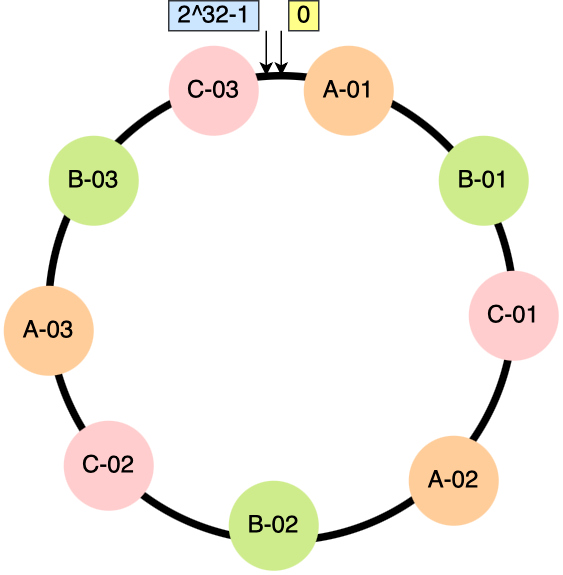
一致性hash就是为了解决分布式环境中节点扩容或者缩容时发生过多数据迁移的问题,该算法是对 232 进行取模运算,也就是是对于一个固定的值进行取余,并且把取余运算的结果值组成一个圆环,这个圆环就称为哈希环。

所以当数据计算落点时,根据一致性hash计算出值,然后按顺时针的方向找到一个节点
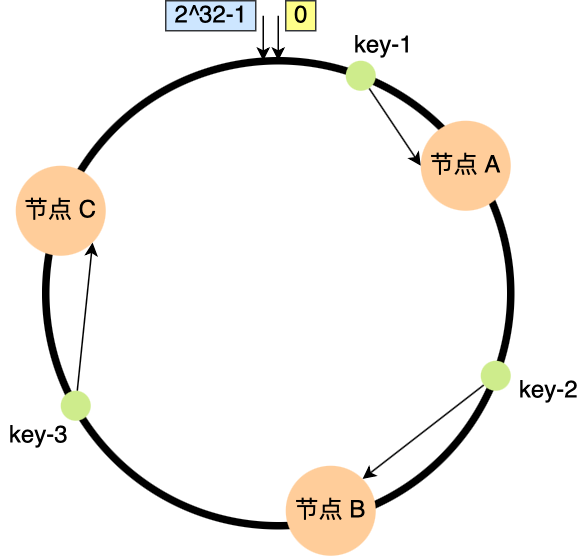
当增加新节点时,只需要把一部分的数据进行迁移,如下面需要迁移部分节点B的数据
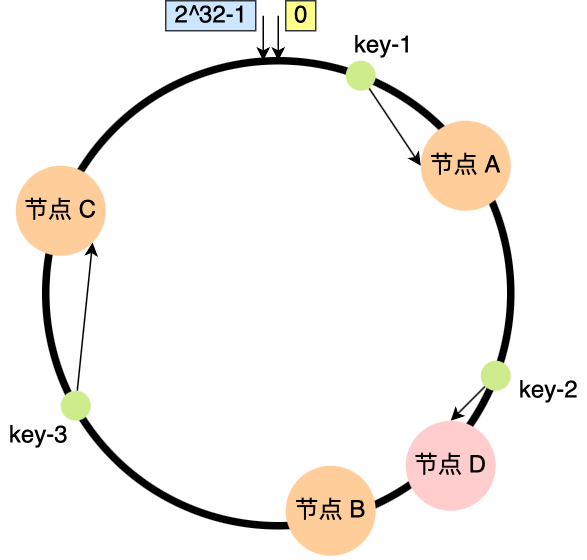
当删除新节点时,只需要把删除的节点的数据顺序的迁移到下一个节点即可
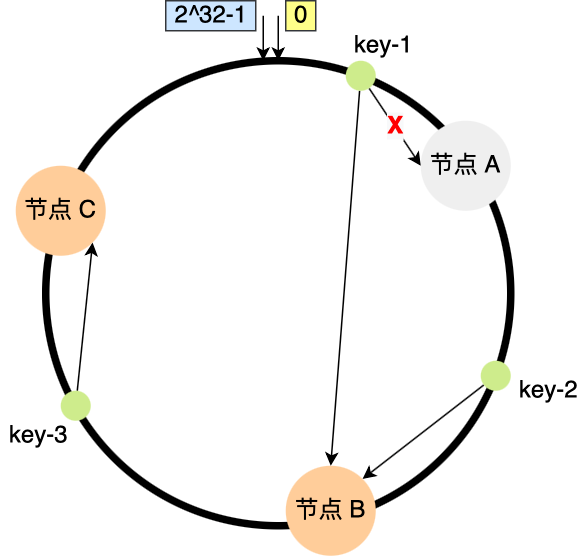
因此,在一致 hash 算法中,如果增加或者移除一个节点,仅影响该节点在哈希环上顺时针相邻的后继节点,其它数据也不会受到影响。
一致性hash的问题
一致性 hash 算法不保证节点能够在哈希环分布均匀,因此会造成数据倾斜的问题。如下图所示:
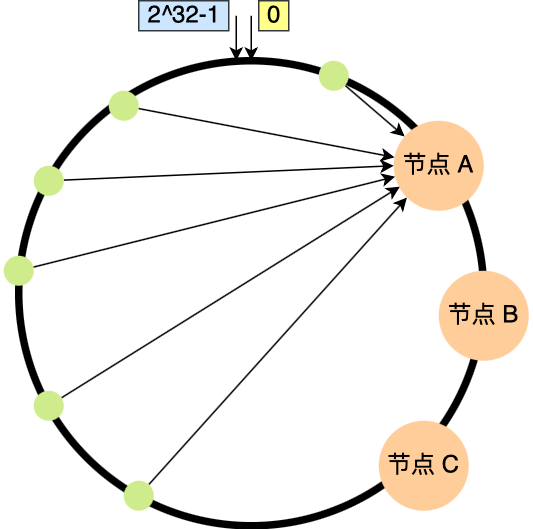
解决的方式就是为每个节点增加虚拟节点,这样就可以使实际节点在环上分布相对均匀