Redis 架构
先从 Redis 架构入手看下在系统底层是如何管理过期键值对的
redisServer
当我们启动 Redis 时,会创建一个redisServer结构体,保存了当前服务器的信息,以及当前所有的数据库信息
struct redisServer {
// ...
redisDb *db; // 数据库列表
// ...
int dbnum; // 数据库数量
// ...
}
Redis 默认的数据库数量是16个,在配置redis/redis.conf中可进行配置修改,可以通过下面这张图表示:
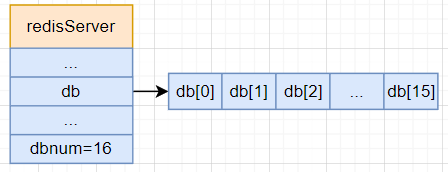
注:Redis 数据库是无法指定名字的,只能根据数组下标表示,通过 SELECT xx 的方式进行切换,默认连接数据库是 0 号数据库
redisDb
从上面可以知道每个数据库对应的是redisDb结构体,该结构体的定义如下:
typedef struct redisDb {
dict *dict; // 一个字典结构,保存了当前数据库下所有的键值对信息,key固定为字符串类型,value可以是任意类型
dict *expires; // 保存了含有过期时间的键值对信息
// ...
int id; // 数据库编号,对应上层数组的下标
// ...
} redisDb;
可以看到对于具有过期时间的键值对是会存放到一个独立的字典中,所以 Redis 可以高效的实现对键值对有效期管理,以下图表示:
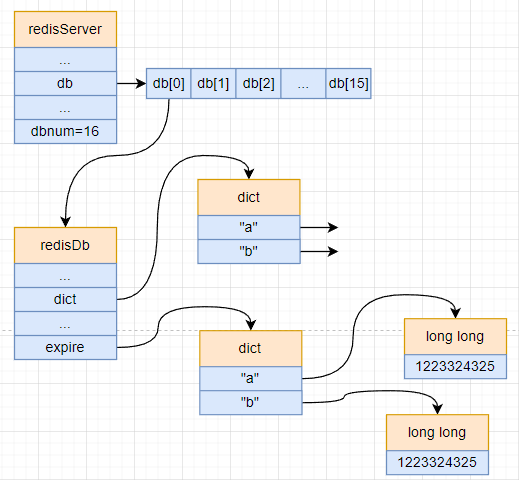
过期删除
设置过期时间
Redis 支持直接对某个已经存在的 key 进行过期时间的设定,有以下 4 个命令:
expire <key> <n> // 设置 key 在 n 秒之后过期
pexpire <key> <n> // 设置 key 在 n 毫秒后过期
expireat <key> <n> // 设置 key 在某个时间戳之后过期,单位秒
pexpireat <key> <n> // 设置 key 在某个时间戳之后过期,单位毫秒
Redis 也支持在设置键值对时直接设置过期时间,有以下 3 个命令:
set <key> <value> ex <n> // 设置键值对时,指定 n 秒之后过期
set <key> <value> px <n> // 设置键值对时,指定 n 毫秒之后过期
setex <key> <n> <value> // 设置键值对时,指定 n 秒之后过期
查看某个键的过期时间,有以下命令:
TTL <key> // 显示 key 剩余的过期时间,如果 key 没有过期时间,则返回 -1
取消某个键的过期时间,有以下命令:
persist <key> // 取消 key 的过期时间
过期键读取流程
从上面的介绍我们知道,键的过期时间保存在redisDb.expire字段中,是一个dict结构。
当客户端要读取键值对时,流程如下:
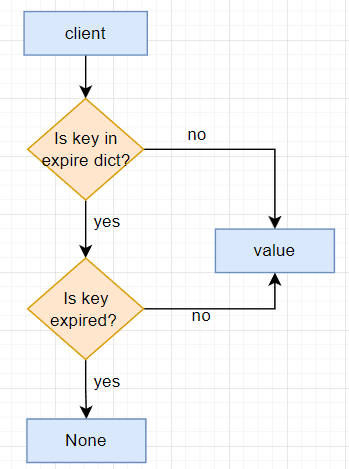
过期删除策略
惰性删除
当 key 过期时,不主动删除该过期的 key,而是等待下一次对该 key 进行读写时,判断到该 key 已过期后再进行删除
优缺点
惰性删除的方式对 CPU 比较友好,但是会占用额外的内存空间,造成内存浪费
定期删除
每隔一段时间(可通过修改redis.conf配置修改,默认是 10 hz,即 1/10 = 100 ms)随机的从数据库中抽取一定数量(源码强制写死为20个)的 key 进行检查,删除其中已经过期的 key
删除流程
- 从过期字典中随机抽取 20 个 key
- 检查这 20 个 key,删除其中已过期的 key
- 如果本轮检查已过期的 key 的数量超过
5个,即如果过期 key 的数量超过25%,则重复步骤1,否则等待下一轮检查
Redis 为了避免长期阻塞线程,限定了上述的删除流程最多只能运行25ms,当超过时则强制停止,等待下一轮检查
内存淘汰
当 Redis 运行时所需要的系统内存已经不足时,将会使用内存淘汰机制来淘汰一些符合条件的 key,以保障系统的运行
Redis 的最大运行内存
在redis.conf配置文件中,通过maxmemory <bytes>进行设定,只有在 Redis 所用内存达到该配置值才会触发内存淘汰机制:
- 在 64 位系统中,该值默认是
0,即永远不进行内存淘汰 - 在 32 位系统中,该值默认是
3G,这是因为 32 位系统最大内存也就 4G内存淘汰策略
Redis 支持设置不同的淘汰策略,有以下几种:
- noeviction:
不进行内存淘汰,Redis3.0 之后默认的淘汰策略,即当运行内存超过最大设置内存时也不淘汰任何数据,而是直接不提供服务。这种策略考虑是任何情况下的内存淘汰都会是对已有数据的篡改,因此为了避免进一步引发不可预期的错误,直接停止服务更加安全
- volatile-random:
随机淘汰设置了过期时间的任意值
- volatile-ttl:
优先淘汰更早过期的键
- volatile-lru:
根据lru规则淘汰设置了过期时间的键,Redis3.0 之前的默认策略
- vola-lfu:
根据lfu规则淘汰设置了过期时间的键,Redis4.0 之后新增的规则
- allkeys-random:
随机淘汰任意键
- allkeys-lru:
根据lru规则淘汰任意键
- allkeys-lfu:
根据lfu规则淘汰任意键
LRU 和 LFU 的区别
LRU
全称为最近最少使用规则,会选择淘汰最近最少使用的数据。传统的 LRU 算法是基于链表结构,即按照数据的操作顺序从前往后排序,最新操作的数据会被移动到链表前端。当需要进行内存淘汰时,直接从链表尾部开始删除到目标数量即可。
传统实现的优缺点
因为使用链表串联的形式,在删除数据时已经处于有序的状态,因此删除方便。但是链表结构也带来了额外的内存开销,因为至少要保存链表的前后节点指针。此外如果同时有大量数据被访问,则会触发频繁的链表移动,这会增加耗时。同时还会有 缓存污染问题,即一次性读取了大量的数据,导致这些数据都被移动到链表头部,但是实际大部分数据只会被读取一次,那么这些数据最终会长时间停留在内存中才会被删除,造成缓存污染问题。
Redis 实现的 LRU
为了避免链表结构带来的额外内存开销,Redis 在每个对象结构中使用一个字段,用以记录数据的最后一次访问时间
typedef struct redisObject {
...
// 24 bits,用于记录对象的访问信息
unsigned lru:24;
...
} robj;
当进行内存淘汰时,采用的是随机抽取的方式,每次抽取5个键(可配置),然后淘汰最久未使用的键。Redis 实现的 LRU 策略虽然占用更少的内存,但是也仍然无法处理内存污染的问题
LFU
全称为最近最不常用规则,会根据数据的访问频率来淘汰数据,核心思想是:如果数据过去被多次访问,那么将来被访问的概率也会更高
Redis 对于 LFU 的实现依然只是沿用了redisObject.lru字段,将这24bits的字段分为了两段存储,高16bits存储上次访问的时间(ldt),后8位记录访问的频次(logc)
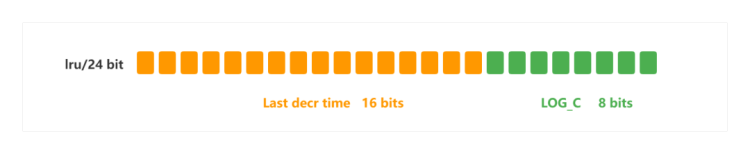
logc的设计
对于每个新键的 key,该值默认为5,且该值会随时间推移而衰减。每当 key 被访问,先根据已保存的ldt和当前时间戳计算衰减值,对 logc 值进行衰减。当上一次访问时间和本次访问时间间隔越大,则衰减幅度越大,这样即实现了根据访问频次来淘汰数据,而非单纯的访问次数。当衰减操作完成之后,再根据一定概率对 logc 进行增长,且该值越大,增长概率越低,这样可以使旧热 key 保持一个相对稳定的 logc 值,而不会与新加入的热 key 存在过大的差距,造成新热 key 无法驻留的问题。
在redis.conf中,由以下参数进行配置:
lfu-decay-time:衰减时间系数,这是一个以分钟为单位的数值,默认为 1,即代表每 1 分钟衰减一次。该值越大,衰减越慢lfu-log-factor:调整增长的速度,该值越大,则增长越慢
LRU 的其他设计
上面说了 Redis 为了避免缓存污染的问题,引入了 LFU 机制,而 MySQL 在淘汰脏页依据的则是改良过的 LRU 机制,他也能够有效的避免缓存污染问题。MySQL 在实际生产环境中,不可避免的会伴随有大规模的范围查询,像是预读机制或者是全表扫描等,这会一次性把大量数据加载到缓存中,如果直接使用原始的 LRU 机制,那么显而易见的会使大量的热点数据被冷数据替换淘汰掉,而后这些冷数据就又会被热数据重新替换,这就造成了一种低效的内存加载卸载循环。
为了规避这点,MySQL 在实现LRU List中规定了一个midpoint位置,这个位置由配置项innodb_old_blocks_pct控制,默认是在链表尾部的37%处,根据这个位置,把整个 List 划分为了 Old 和 New 两个区域,如下图所示:
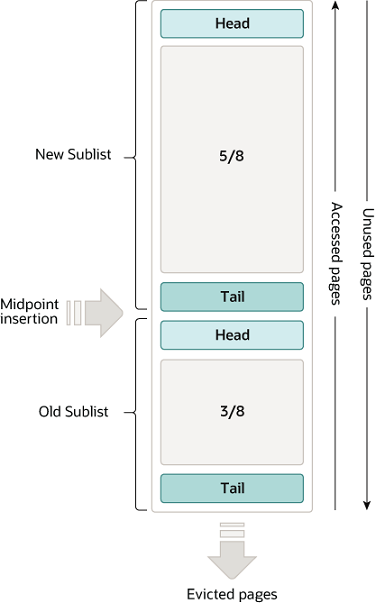
当数据被访问时,会被加载到midpoint位置,即 Old 区域的头部,并且在配置项innodb_old_blocks_time时间内,默认值是 1000ms,该数据被再次访问是不会将其转移到 New 区域的头部,而是要等到这个配置时间之后,如果数据还存在 Old 区域且再次被访问了那么说明这是一份热数据,才会被移动到 New 区域。通过这种设计,就可以有效的避免缓存污染问题了。