Basic Paxos
Basic Paxos 论述的是在分布式架构下,对于一个变量同时出现不同的值时,如何对该变量的值形成共识性,是一种理论研究模型。注意后面分析中探讨的是如何对这不同的值达成共识的过程
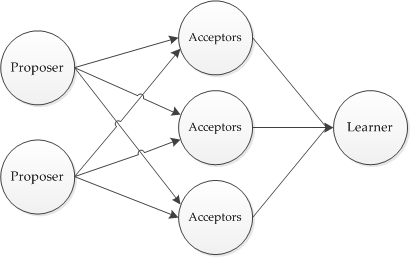
三种身份
对于分布式架构中的每一个节点都可能处于以下三种身份:proposer、acceptor、learner,注意可以同时!!所有节点的身份都是平等的,这是和 raft 的重要区别
- proposer:提案者。接收到客户端写操作的节点,本身也是一个 acceptor
- acceptor:接收者。负责对提案者提出的命令作出决定
- learner:学习者。接收已经达成共识的命令,对于这个角色不是很理解,在工程项目中,理论上所有的节点都应该参与投票,即至少为 acceptor
三者形成的关系如下:
全局唯一递增的序列
对于序号的要求,必须是全局唯一的,且在单节点上必定是严格递增,而不同节点之间只需要满足趋势递增即可。所以这个序号的组成一般采用时间戳 + 节点标识(如服号)+ 自增值的形式组成,这样就可以保证单服的严格递增,而不同节点之间由于含有时间戳的缘故,也是趋势递增的。在 Chubby 中提出了一种计算方法,也可以参考使用:假设有 n 个 proposer,且编号为 ir (0 <= ir < n),则 ID = m * n + ir (m初始为0,每次生成新序号时则递增,且应持久化)。也可以使用snowflake算法生成时间戳
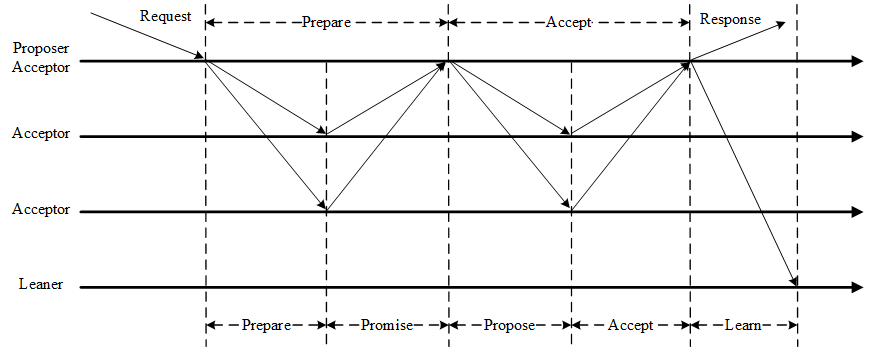
二阶段协议
当 proposer 接收到客户端的消息之后,会通过二阶段协议将消息分发到其余 acceptor 节点,总的交互流程可以按下图划分
Prepare - Promise
Prepare
当 proposer 接收到客户端消息,proposer 将会生成一个唯一且递增的 proposal ID,并通过 PREPARE_RPC发送给集群中的其他 acceptor 节点。
伪代码如下:
proposal_ID = new_proposal_ID()
send PREPARE(proposal_ID)
Promise
每个 acceptor 接收到 PREPARE_RPC之后,将会依据 RPC 中的 proposal ID进行判断。
伪代码如下:
if (ID <= max_id)
do not respond (or respond with a "fail" message)
else
max_id = ID // save highest ID we've seen so far
if (proposal_accepted == true) // was a proposal already accepted?
respond: PROMISE(ID, accepted_ID, accepted_VALUE)
else
respond: PROMISE(ID)
当 acceptor 接收到PREPARE_RPC时,节点的状态可能正处于以下三种情况之一:
- 之前从未接收到
PREPARE_RPC - 之前已经接收到
PREPARE_RPC,但还未接收到PROPOSE_RPC - 之前已经接收到
PREPARE_RPC,且已经接收到PROPOSE_RPC,并缓存了VALUE
无论处于何种状态,acceptor 必须只能接受值更大的proposal ID,这保障了提案的顺序性。如果 acceptor 已经缓存了VALUE,表示在该 proposer 之前,已经有其他的 proposer 向 acceptor 发出了提案,该提案有可能已经达成了共识,也可能还没有。不管该accepted_VALUE是否已经达成了共识,当前 proposer 的提案是属于后来者,被接收的可能性更低,所以当前的 proposer 需要接受这份提案,转而 _协助 _传播这份提案
acceptor 至少需要持久化 max_id、accepted_ID、accepted_VALUE
Propose - Accept
Propose
当 proposer 接收到绝大部分 acceptor 节点返回的 PROMISE信息,即可通过 PROPOSE_RPC下发proposal ID和Value。
伪代码如下:
did I receive PROMISE responses from a majority of acceptors?
if yes
do any responses contain accepted values (from other proposals)?
if yes
val = accepted_VALUE // value from PROMISE message with the highest accepted ID, so current proposer will help propose the consensus value
if no
val = VALUE // we can use our proposed value
send PROPOSE(ID, val) to at least a majority of acceptors
else
send new prepare // to avoid crash
这里需要额外考虑一种情况,如果同时有多个 proposer 发起了PREPARE_RPC,且值最大的 RPC 最先被接收,那么其余的RPC将会得不到回复(或者收到 “fail” 信息),如果此时最大的 proposer 宕机了,则整体的集群服务将会陷入停滞状态
因此,当 proposer 在提案遭到过半数的拒绝时,需要更新自己的提案号,用新的更大的提案号,去发起新的 prepare 请求。(这会造成活锁问题,即可能这边刚提了一个更大的提案号然后宕机,转而另一个又提了一个更大的提案,依次反复)
Accept
当 acceptor 接收到PROPOSE_RPC之后,根据协议中的proposal ID进行判断
伪代码如下:
if (ID >= max_id) // is the ID the largest I have seen so far?
proposal_accepted = true // note that we accepted a proposal
accepted_ID = ID // save the accepted proposal number
accepted_VALUE = VALUE // save the accepted proposal data
respond: ACCEPTED(ID, VALUE) to the proposer and all learners
else
do not respond (or respond with a "fail" message)
在此阶段,acceptor 也需要只接受值更大的proposal ID的提案。如果接收到的proposal ID小于已保存的最大ID,则说明虽然该 proposer 在之前已经通过PREPARE_RPC收到了绝大部分的 acceptor 的认可,但是还未来得及发出相对应的 proposal 提案,而后续又有新的 proposer 提出了新的提案,因此不能接收这份旧的提案
如果 proposer 收到了失败的回复,说明本节点的提案号是小于 acceptor 的提案号的,则本节点需要更新自己的提案号,然后再去发起新的 prepare 请求。这种情况下重新发出的 prepare 请求到达 acceptor 时,如果 acceptor 已经拥有了accepted_VALUE,则 proposer 会更新自己的VALUE,因此原先的accepted_VALUE依然会达成共识。(这会造成活锁问题)
几个例子
注:所谓的 chosen 是指集群中绝大部分的节点都达成了共识
提案已被chosen,并接收到新的提案
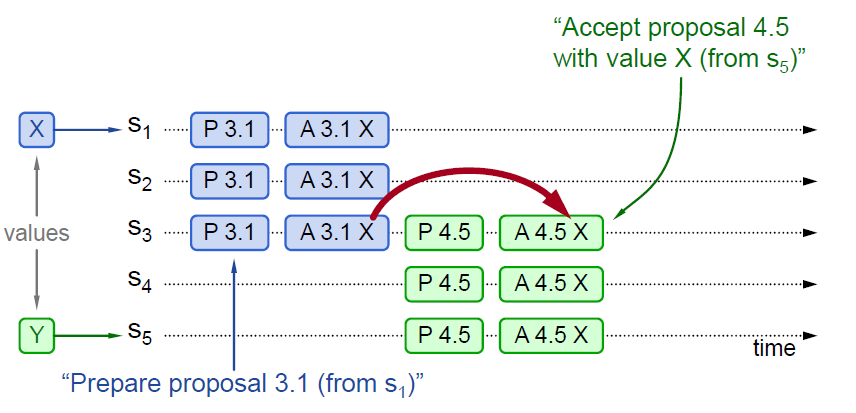
- S1收到了客户端值为X的提案,此时S1的身份是 proposer + acceptor,于是S1向所有节点(包括自身)下发
Prepare(3.1),并得到了S1 - S3 的回应 - 由于S1 - S3回应的
PROMISE信息没有包含其他已经接收的VALUE,因此S1向所有节点下发Accept(3.1, X),注意如果S4-S5在这个阶段接收到该RPC,同样也会执行,因为这个提案号是当前最大的 - S5收到了客户端值为Y的提案,并向所有节点广播
Prepare(4.5),并得到了S3 - S5的回应 - 由于S3的回应中携带了
accepted_VALUE信息,因此S5更新自己的VALUE信息为accepted_VALUE,并且进一步广播Accept(4.5, X),_协助 _传播这份提案,因此最终达成共识
提案未被chosen,并接收到新的提案,proposer可见
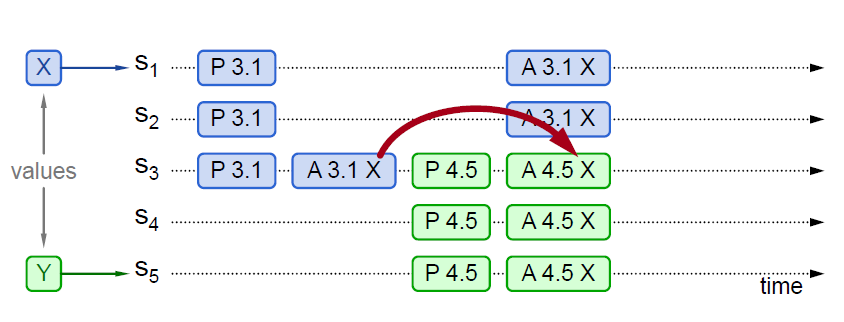
- S1收到了客户端值为X的提案,此时S1的身份是 proposer + acceptor,于是S1向所有节点(包括自身)下发
Prepare(3.1),并得到了S1 - S3 的回应 - 由于S1 - S3回应的
PROMISE信息没有包含其他已经VALUE,因此S1向所有节点下发Accept(3.1, X),但是只有S3立即接收到了该 Accept 信息,其余节点由于网络原因,接收时机发生了延后 - S5收到了客户端值为Y的提案,并向所有节点广播
Prepare(4.5),并得到了S3 - S5的回应 - 由于S3的回应中携带了
accepted_VALUE信息,因此S5更新自己的VALUE信息为accepted_VALUE,并且进一步广播Accept(4.5, X),_协助 _传播这份提案,因此最终达成共识。如果S5的 Accept 信息也被S1 - S2接收到,则只会转变S1 和 S2的max_id,对于提案内容不会变化
提案未被chosen,并接收到新的提案,proposer不可见
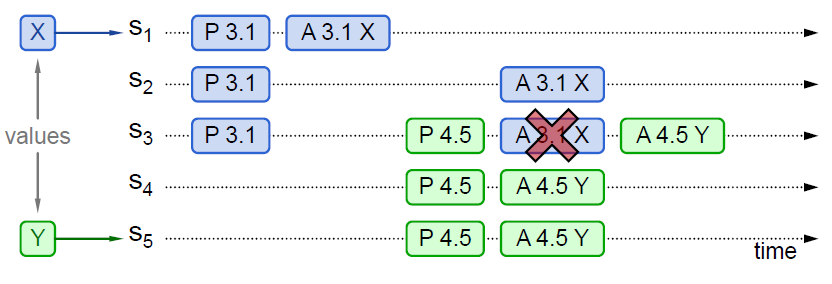
- S1收到了客户端值为X的提案,此时S1的身份是 proposer + acceptor,于是S1向所有节点(包括自身)下发
Prepare(3.1),并得到了S1 - S3 的回应 - 由于S1 - S3回应的
PROMISE信息没有包含其他已经VALUE,因此S1向所有节点下发Accept(3.1, X),但是只有S1立即接收到了该 Accept 信息,其余节点由于网络原因,接收时机发生了延后 - S5收到了客户端值为Y的提案,并向所有节点广播
Prepare(4.5),并得到了S3 - S5的回应,在S3进行回应时还未接收到Accept(3.1, X)信息 - 由于所有的回应都不携带
VALUE信息,因此S5直接广播Accept(4.5, Y)。此时虽然S3接收到了Accept(3.1, X)信息,但是由于3.1 < 4.5,因此并不会对该信息进行应答,只有当接收到Accept(4.5, Y)才发生应答,因此达成共识 - S1 - S2 如果在后续接收到 S5 因为延迟而到来的
Accept(4.5, Y),根据 accept 阶段的伪代码可知,将会丢弃 X 值而选择 Y值,因为它拥有更大的proposal ID
活锁问题
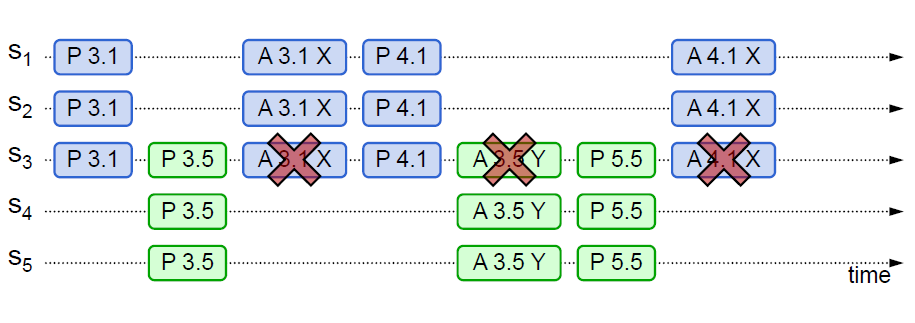
由于当 proposer 的提案得不到绝大部分 acceptor 的共识时,需要更新提案号,然后再发起 prepare 请求
解决活锁问题,常见的解决方式有几种:
- 当 proposer 接收到回复之后,如果发现未能获得绝大多数 acceptor 的共识,则不立即更新编号,而是随机延迟一段时间后,再进行更新尝试
- 设置一个 proposer 的 leader, 由该 leader 进行全部的提案,这是常见的解决方案,实际上就演变为
Multi Paxos了。Raft、ZAB实际上也是这种方案的实现思路
异常分析
如果 acceptor 在接收到 PREPARE_RPC 后宕机或者回复的 PROMISE 消息丢失了,会发生什么?
如果 proposer 依然可以在集群的绝大多数的 acceptor 收获到 PROMISE 回复,则部分 acceptor 的宕机将不会影响集群整体的运行。否则 proposer 会一直重发 PREPARE_RPC,直到接收到回复,或者被重置
如果 acceptor 在接收到 PROPOSE_RPC 后宕机或者回复的 ACCEPT 消息丢失了,会发生什么?
如果 proposer 依然可以在集群的绝大多数的 acceptor 收获到 ACCEPT 回复,则部分 acceptor 的宕机将不会影响集群整体的运行。否则 proposer 会一直重发 PROPOSE_RPC,直到接收到回复,或者被重置
如果 proposer 在 Prepare 阶段宕机了,会发生什么?
如果 proposer 在发出 PREPARE_RPC 之前宕机的,则等价于没有执行,对于客户端来说,会收到执行失败的反馈。当 proposer 是在发出 PREPARE_RPC 之后宕机的,不管 acceptor 是否接收到消息,最终都无法对该proposal ID达成共识,最终 acceptor 的状态也会应该接收到新的更大的proposal ID重置
如果 proposer 在 Propose 阶段宕机了,会发生什么?
如果是在发出 PROPOSE_RPC 之前宕机,则和 proposer 是在发出 PREPARE_RPC 之后宕机的情形是一样的。如果是在发出 PROPOSE_RPC 之后宕机,如果发去的消息成功被 acceptor 接收,那么只要当该 acceptor 接收到其他 proposer 下发的版本更高的proposal ID,并返回PROMISE(higher-ID, <old_ID, Value>),则对应的 proposer 会更新自己的VALUE信息,并代替宕机的 proposer 节点完成后面的任务,此时消息依然能够达成共识
当想要读取 acceptor 上的值时,需要经过多一轮 Basic paxos 共识
假设集群中有5个 acceptor,其中2个 acceptor 接收了值X,另外3个acceptor接收了值Y,由于出现了网络分区,两个子分区之间没有能够继续交互,也就造成了虽然Y在集群中达成了共识,但是并不是整个集群的节点都保留了该值。因此在实际应用该值时,还需要经过一轮 Basic Paxos,只有得到绝大数节点的认可后,才能表明当前值的正确性。
Multi Paxos
Basic Paxos 是无法连续确定多个值的共识性的,而且容易存在活锁的问题,而通过 Multi Paxos 正是解决该问题的方案,相较于 Basic Paxos 有两点改进:
- 选择一个 leader 作为唯一的 proposer,取消多 proposer,因为没有提案的竞争,也就不会有活锁问题。同时也就可以取消 prepare 阶段,因为不需要再协商判断,唯一的 Leader 具有权威性
- 对于每一次要确定的值,都使用唯一的标识区分
和 Raft 不同的是 Multi Paxos 允许:
- 乱序 commit
- 乱序 execute(当然这个要取决于上层状态机对数据顺序是否有要求)
- 多写
- 多读
这明显的一个问题就是在数据库层面的应用,比方说同时有事务4 ~ 事务8,每个事务之间没有关联性,但是假设事务4没有被持久化,则在 raft 中事务5~事务8就会一直被阻塞