Python 的运行
Python 语言的类型
我们一般说 Python 是一门解释型的语言,因为它可以通过Python code.py的方式直接运行代码,而无需像编译型语言如 C++ 那样需要先经过编译才可以运行
我们来做个测试:
## main.py
def Fun1():
print("Python 是解释型语言吗?")
if __name__ == '__main__':
Fun1()
在命令行中,直接运行 main.py,输出如下:
>>> python main.py
Python 是解释型语言吗?
查看文件夹也没有额外文件产生,这符合解释型语言的特征
再做个测试,在 main.py 导入其他模块
## code.py
def Fun2():
print("code.py 中的 Fun2 函数")
## main.py
import code
def Fun1():
print("Python 是解释型语言吗?")
code.Fun2()
if __name__ == '__main__':
Fun1()
再次运行,得到的输出如下:
>>> python main.py
Python 是解释型语言吗?
code.py 中的 Fun2 函数
此时查看文件夹,可以看到在程序运行之后,创建了文件夹__pycache__和新文件code.cpython-36.pyc
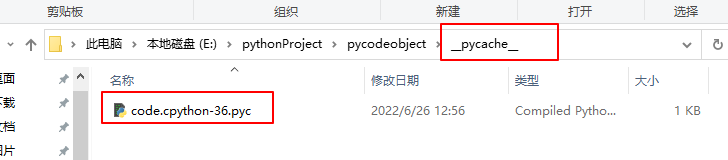
创建出来的.pyc文件,实际上就是一种编译后文件,当我们对某个文件进行import操作时,Python 就会为我们创建对应的.pyc文件,以备程序重复运行时使用。所以 Python 实际上是一种需要先编译后再运行的程序,这类似于 Java 语言,只不过 Python 的解释器同时充当了编译器和虚拟机的角色

而之所以没有为 main.py 文件生成.pyc文件,是因为解释器认为这是一个一次性的运行文件,Python 解释器不会为可能只运行一次的文件生成 pyc 文件,而在后续再次导入code.py时,优先就会使用.pyc文件进行反序列化
.pyc 文件内容
.pyc文件是一个二进制文件,他的内容是无法直接解读的,从它生成的规则来说,一个.pyc文件包含以下四种数据信息:
- 一个 4 字节的
magic number - 一个 4 字节的文件修改时间
- 一个 4 字节的源文件大小
- 一个经过序列化的 PyCodeObject 对象
其他后缀文件
除了上面讲到的.py文件和.pyc文件,还有其他几种类型的文件
.pyo 文件
.pyo文件是经过优化的.pyc文件,去除了一些代码行号、断言、文件描述等,具有更小的文件体积,同时具有更快的加载速度,但是并不会加速程序的执行速度。不过在 **PEP 48 **之后就移除了.pyo文件,具体原因是.pyc文件具有两个优化级别,而之前都统一使用.pyo后缀表示,这就带来了一定的混乱性。
而现在这两个优化都统一使用了.pyc文件作为后缀,只是文件名具有一些差别:
- 默认无优化级别:
python -m py_compile code.py,得到文件:code.cpython-36.pyc - 优化级别一:
python -O -m py_compile code.py,得到文件:code.cpython-36.opt-1.pyc - 优化级别二:
python -OO -m py_compile code.py,得到文件:code.cpython-36.opt-2.pyc
.pyw 文件
这个是专门为了 windows 环境下 GUI 开发而设计的模式。在 windows 环境下运行.pyc文件会弹出控制台窗口,这对 GUI 图形界面开发程序不美观。
我们原先生成的code.cpython-36.pyc中因为没有输出语句,因此直接运行是察觉不到控制台窗口的创建的,先加入以下测试代码
def Fun3():
print("sleep now")
sleep(5)
Fun3()
双击运行重新生成的.pyc文件,就可以看到生成的控制台窗口了

当程序识别到.pyw文件,系统会使用pythonw.exe程序运行,这屏蔽了代码中的stdout、stderr入口,因此就不会有消息输出到控制台了。使用的是以下可执行文件运行代码:
.pyd 文件
.pyd文件格式是通过 D 语言编译后生成的二进制文件,这种文件无法被反编译,因此安全性较高
PyCodeObject 对象
我们已经知道,Python 代码在编译之后,会存储在.pyc文件并持久化在磁盘上,而.pyc文件的主要内容就是PyCodeObject对象,这个对象存储了代码运行所需要的一切信息。Python 解释器在遇到会把原始代码编译为PyCodeObject对象,在 CPython 中,该对象的定义如下:
typedef struct {
PyObject_HEAD
int co_argcount; // 位置参数个数
int co_kwonlyargcount; // kv参数的个数,即*号之后的参数个数
int co_nlocals; // 局部变量个数
int co_stacksize; // 所需要的栈空间数
int co_flags; // 标识,用以表示当前PyCOdeObject对应的类型,作 bitmap 用
int co_firstlineno; // 在 .py 原码中的起始行
PyObject *co_code; // 经过编译后的字节码序列
PyObject *co_consts; // 当前作用域使用到的常量,嵌套的 code 对象也存储在这里
PyObject *co_names; // 除了函数参数和函数局部变量之外的变量,这个在 CPython3.6 中描述有误,直到CPython3.9才修正了描述
PyObject *co_varnames; // 当前作用域中使用到的局部变量
PyObject *co_freevars; // 当前是闭包作用域,则此处包含的是使用到的外层作用域的变量
PyObject *co_cellvars; // 如果本作用域包含了闭包作用域,则此处包含的是被闭包作用域使用到的定义在本作用域中的名字
unsigned char *co_cell2arg; // 映射上面cell—_vars中是函数参数的变量
PyObject *co_filename; // 创建出当前 PyCodeObject 的文件名路径
PyObject *co_name; // 当前 PyCodeObject 的名称
PyObject *co_lnotab; // 行数信息表,保存了字节码和源码的行数映射关系
void *co_zombieframe; // PyCOdeObject 对象第一次和 PyFrameObject 对象绑定时,在执行完之后,PyFrameObject 对象不会释放,而是进入“zombie”状态存储在此处,以便后续再利用,这样可以节省内存申请/释放的开销
PyObject *co_weakreflist; // 弱引用相关
void *co_extra; // 存储了指向 _PyCodeObjectExtra 对象的指针,用于扩展
} PyCodeObject;
名字空间和作用域
Python 解释器在运行时,针对代码中的每一个Code Block都会创建一个PyCodeObject对象,而这个Code Block就是等价于我们之前平时一直提到的 名字空间。
根据官方文档,命名空间指的是从名称到对象的映射关系,一般是通过 Python 字典实现,而作用域指的是可以访问到命名空间的正文区域。这两个概念有点绕,不过从上面的概述可以知道命名空间实际对应的是 字典,是具有实体的,而作用域只是一种对于访问范围的描述,从这点入手就可以比较好的理解这两个概念了。
Python 的作用域一共有4种,分别是:
- L(Local):最内层,包含局部变量,比如一个函数/方法内部。
- E(Enclosing):包含了非局部(non-local)也非全局(non-global)的变量。比如两个嵌套函数,一个函数(或类) A 里面又包含了一个函数 B ,那么对于 B 中的名称来说 A 中的作用域就为 nonlocal。
- G(Global):当前脚本的最外层,比如当前模块的全局变量。
- B(Built-in): 包含了内建的变量/关键字等,最后被搜索。
而 Python 的名字空间则分为3种,分别是:
- 局部名字空间:函数或类中定义的名字空间,包括了参数和局部定义的变量
- 全局名字空间:模块定义的名字空间,包括了函数、类、其他模块导入的变量等
- 内建名字空间:Python 内置的变量名称
字段解析
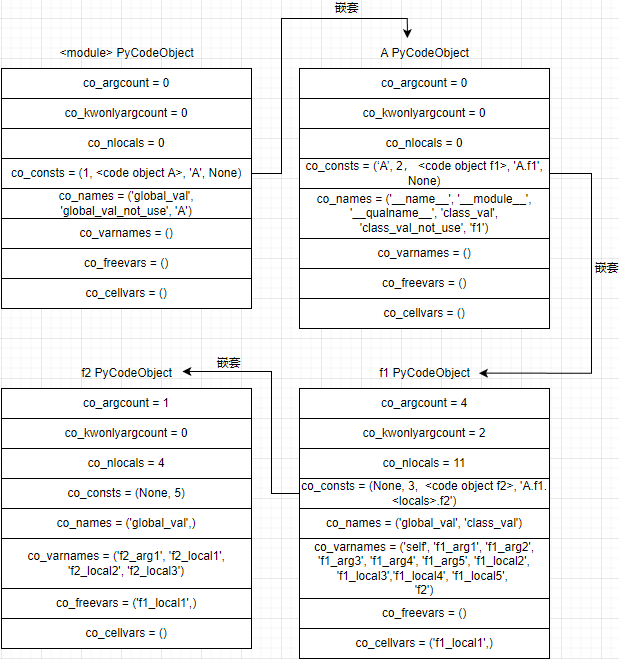
以下面的代码为例,我们来探究下名字空间和PyCodeObject的对应关系
>>> test = """
global_val = 1
global_val_not_use = global_val
class A():
class_val = 2
class_val_not_use = class_val
def f1(self, f1_arg1, f1_arg2, f1_arg3, *, f1_arg4, f1_arg5):
f1_local1 = 3
f1_local2 = global_val
f1_local3 = class_val
f1_local4 = f1_arg1
f1_local5 = f1_local4
def f2(f2_arg1):
f2_local1 = 5
f2_local2 = f1_local1
f2_local3 = global_val
return f2
"""
>>> m_code = compile(test, 'test_codeobject.py', 'exec')
<code object <module> at 0x0000023833675C00, file "test_codeobject.py", line 2>
通过上述代码,我们得到了一个对应着全局名字空间的PyCodeObject,即一个模块的 code 对象。这其实相当于我们定义了一个名为test_codeobject.py的文件,而其内容定义如下:
global_val = 1
global_val_not_use = global_val
class A():
class_val = 2
class_val_not_use = class_val
def f1(self, f1_arg1, f1_arg2, f1_arg3, *, f1_arg4, f1_arg5):
f1_local1 = 3
f1_local2 = global_val
f1_local3 = class_val
f1_local4 = f1_arg1
f1_local5 = f1_local4
def f2(f2_arg1):
f2_local1 = 5
f2_local2 = f1_local1
f2_local3 = global_val
return f2
下面我们就依照这个模块中的代码,分别解析一些主要字段的意义
co_consts
该字段主要存储的是当前名字空间中的常量和包含的 code 对象
# 先查看模块对应的 PyCOdeObject 对象
>>> m_code.co_consts
(1, <code object A at 0x0000023833675930, file "test_codeobject.py", line 4>, 'A', None)
# 再来查看类对应的 PyCodeObject 对象
>>> A_code = m_code.co_consts[1]
>>> A_code.co_consts
('A', 2, <code object f1 at 0x0000023833675B70, file "test_codeobject.py", line 7>, 'A.f1', None)
# 继续深入看函数f1对应的 PyCodeObject 对象
>>> f1_code = A_code.co_consts[2]
>>> f1_code.co_consts
(None, 3, <code object f2 at 0x0000023833675AE0, file "test_codeobject.py", line 11>, 'A.f1.<locals>.f2')
# 最后看函数f2对应的 PyCodeObject 对象
>>> f2_code = f1_code.co_consts[2]
>>> f2_code.co_consts
(None, 5)
co_argcount
这个字段存储的是函数的位置参数的个数,当函数的参数含有独立的一个*号时,则在*号之前的参数只能使用位置参数
# f1函数的位置参数
>>> f1_code.co_argcount
4 # 这里包含了 self 参数,所以是 4 个
# f2函数的位置参数
>>> f2_code.co_argcount
1
co_kwonlyargcount
这个字段存储的是函数中的键值对参数的个数,当函数的参数含有独立的一个*号时,则在*号之后的参数只能使用键值对参数
# f1函数的键值对参数
>>> f1_code.co_kwonlyargcount
2
# f2函数的键值对参数
>>> f2_code.co_kwonlyargcount
0
co_nlocals 和 co_varname
这个字段存储的是局部变量个数,而且只是co_varnames的计数
# 模块的局部变量
>>> m_code.co_nlocals
0
>>> m_code.co_varnames
()
# 类的局部变量
>>> A_code.co_nlocals
0
>>> A_code.co_varnames
()
# f1的局部变量数
>>> f1_code.co_nlocals
11
>>> f1_code.co_varnames
('self', 'f1_arg1', 'f1_arg2', 'f1_arg3', 'f1_arg4', 'f1_arg5', 'f1_local2', 'f1_local3', 'f1_local4', 'f1_local5', 'f2') # 这里可以看出函数的参数都属于局部变量,不管该参数在函数内是否被调用(如f1_arg1),而函数内的变量如果被内部的闭包函数使用了,则该变量不属于局部变量(如f1_local1)
# f2的局部变量
>>> f2_code.co_nlocals
4
>>> f2_code.co_varnames
('f2_arg1', 'f2_local1', 'f2_local2', 'f2_local3')
co_names
该字段存储的是除了函数参数和函数局部变量之外的变量(包含了全局变量、导入变量等)。当使用global关键字修改变量时,则编译器会从co_names中查找目标变量,如果查找不到则会报错
# 模块
>>> m_code.co_names
('global_val', 'global_val_not_use', 'A')
# 类
>>> A_code.co_names
('__name__', '__module__', '__qualname__', 'class_val', 'class_val_not_use', 'f1')
# 函数f1
>>> f1_code.co_names
('global_val', 'class_val')
# 函数f2
>>> f2_code.co_names
('global_val',)
co_freevars
当前是闭包作用域,则此处包含的是使用到的外层作用域的变量。当使用nonlocal关键字修改变量时,则编译器会从co_freevars中查找目标变量,如果查找不到则会报错
# 模块
>>> m_code.co_freevars
()
# 类
>>> A_code.co_freevars
()
# f1
>>> f1_code.co_freevars
()
# f2
>>> f2_code.co_freevars
('f1_local1',)
co_cellvars
如果本作用域包含了闭包作用域,则此处包含的是被闭包作用域使用到的定义在本作用域中的名字,实际上这个字段是和co_freevars字段相对应
# 模块
>>> m_code.co_cellvars
()
# 类
>>> A_code.co_cellvars
()
# f1
>>> f1_code.co_cellvars
('f1_local1',)
# f2
>>> f2_code.co_cellvars
()
co_filename
当前的文件名
>>> m_code.co_filename
'test_codeobject.py'
>>> A_code.co_filename
'test_codeobject.py'
>>> f1_code.co_filename
'test_codeobject.py'
>>> f2_code.co_filename
'test_codeobject.py'
co_name
当前PyCodeObject对象的名称
>>> m_code.co_name
'<module>'
>>> A_code.co_name
'A'
>>> f1_code.co_name
'f1'
>>> f2_code.co_name
'f2'
co_code
上面介绍到的字段,都属于PyCodeObject对象本身的静态属性,而co_code存储的是执行调用这些静态属性的字节码序列,我们以f2_code.co_code为例进行讲解
dis.dis(f2_code.co_code)
0 LOAD_CONST 1 (1) # 将 co_consts[1] 推入栈顶
2 STORE_FAST 1 (1) # 将栈顶存放到局部对象 co_varnames[1]
4 LOAD_DEREF 0 (0) # 将 co_freevars[0] 推入栈顶
6 STORE_FAST 2 (2) # 将栈顶存放到局部对象 co_varnames[2]
8 LOAD_GLOBAL 0 (0) # 加载 co_names[0] 的全局对象推入栈顶。
10 STORE_FAST 3 (3) # 将栈顶存放到局部对象 co_varnames[3]
12 LOAD_CONST 0 (0) # 将 co_consts[0] 推入栈顶
14 RETURN_VALUE # 返回栈顶元素到调用者
如果传入dis函数的是PyCodeObject对象,即会根据 code 对象上的静态属性,直接展示对应属性名,如
>>> dis.dis(f2_code)
14 0 LOAD_CONST 1 (5)
2 STORE_FAST 1 (f2_local1)
15 4 LOAD_DEREF 0 (f1_local1)
6 STORE_FAST 2 (f2_local2)
16 8 LOAD_GLOBAL 0 (global_val)
10 STORE_FAST 3 (f2_local3)
12 LOAD_CONST 0 (None)
14 RETURN_VALUE
co_firstlineno 和 co_lnotab
这两个字段是用来建立字节码和源码之间的行号映射关系,以在上面使用dis.dis(f2_code)的输出为例:
#源码行号 #字节码序列行号 #字节码 #参数 #实际参数
14 0 LOAD_CONST 1 (5)
字节码序列行号总是0开始,即它代表的意思是当前字节码在co_code中的下标,而源码行号则依赖co_firstlineno字段标记
>>> f2_code.co_firstlineno
13
可以看到这里的co_firstlineno并不等于14,而是等于13。这是因为实际行号,是通过co_lnotab记录的增量值计算的,我们来看下f2_code中该字段的信息
>>> f2_code.co_lnotab
b'\x00\x01\x04\x01\x04\x01' # 每两个16进制为一组
这里用一个表格作为说明
| 源码序号 | 字节码序号 | co_lnotab | |
|---|---|---|---|
| 源码增量 | 字节码增量 | ||
| co_firstlineno = 13 | 0 | ||
| 14 | 0 | 01 | 00 |
| 15 | 4 | 01 | 04 |
| 16 | 8 | 01 | 04 |
PyCodeObject包含的其他信息,这里不做代码演示
最后以一张图作为概括
global 和 nonlocal
Python 的名字查找是按照局部名字空间->全局名字空间->内置名字空间的顺序进行变量名的查找,这意味着如果在前一个名字空间中查找到名字,那么相对应后面的名字空间的同名变量将会被屏蔽。
有时候我们需要强制指定某个变量的查询路径,因此 Python 提供了global和nonlocal这两个关键字,下面我们用代码来看下,这个两个关键字是如何发挥作用的。
global
当程序中不存在同名的局部变量时,不管是否使用global关键字,编译器都会依照名字查找顺序,最终找到定义在全局名字空间中的变量,即会使用LOAD_GLOBAL字节码进行变量的加载,从co_names中查找变量
如下面代码示例:
global_val = 1
def fun1():
# global global_val
fun1_local = global_val
# 经过编译之后,输出字节码(注:忽略无关字节码)
5 0 LOAD_GLOBAL 0 (global_val)
2 STORE_FAST 0 (fun1_local)
当存在同名的局部变量时,不管其定义的位置,都将会对全局变量形成屏蔽,即生成的字节码将会是LOAD_FAST,从co_varnames中查找目标变量
# 屏蔽1:
global_val = 1
def fun1():
global_val = 2
fun1_local = global_val
# 屏蔽2:这种方式容易出错
# 1) 正常代码,使用的是全局变量
global_val = 1
def fun1():
v = global_val + 2
fun1_local = v
# 2) 异常代码,使用的是未定义的局部变量
global_val = 1
def fun1():
v = global_val + 2
global_val = 2
fun1_local = v
为了避免上述代码可能存在的问题,可以使用global关键字强制指定编译器采用LOAD_GLOBAL的方式加载目标变量
global_val = 1
def fun1():
global global_val
v = global_val + 2
global_val = 2
fun1_local = v
# 字节码,使用的是 LOAD_GLOBAL
5 0 LOAD_GLOBAL 0 (global_val)
2 LOAD_CONST 1 (1)
小结:
- 代码中最好避免在不同的名字空间中使用同名的变量
- 在使用全局变量的地方应该都加上
global关键字
nonlocal
nonlocal的语义和global类似,只不过是应用于闭包函数的情景,加载闭包变量的字节码是LOAD_DEREF,这里不做赘述
.pyc 文件
.pyc文件的主要内容上面已经有过简略的介绍,本节我们尝试来解读文件的内容
4种数据信息
magic number
该值是为了辨别.pyc文件版本,不同的 Python 版本编译之后生成的.pyc文件具有不同的magic number。可通过以下代码查看当前 Python 版本的magic number:
>>> import imp
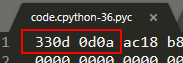
>>> imp.get_magic().hex()
'330d0d0a'
对比上面生成的code.cpython-36.pyc文件的前 4 字节内容,可见是一致的
文件修改时间
文件修改时间记录了当前文件被生成的时间,在代码中会比较当前.pyc文件与.py文件的时间戳,如果发现.pyc文件的修改时间落后于原始文件的时间,则会进行重生成
源文件大小
.py文件的原始大小& 0xFFFFFFFF的结果
序列化的 PyCodeObject 对象
记录了代码执行所需要的所有信息,在后文会继续展开讲解,当后面再使用.pyc文件时,将会重新反序列化生成PyCodeObject对象
源码分析
我们知道当程序对某个模块进行导入时,就会生成对应的.pyc文件,我们从这个过程来看下这个过程对应的底层源码实现。
具体import的底层实现不是本节的关注点,因此一些中间的调用流程这里用一张图来表示:

在_find_and_load函数的实现中,会经过一层层的调用跳转之后,最终调用的是sys.path_hooks中三种loader:
def _get_supported_file_loaders():
"""Returns a list of file-based module loaders.
Each item is a tuple (loader, suffixes).
"""
extensions = ExtensionFileLoader, _imp.extension_suffixes() # 动态库
source = SourceFileLoader, SOURCE_SUFFIXES # .py 文件
bytecode = SourcelessFileLoader, BYTECODE_SUFFIXES # .pyc 文件
return [extensions, source, bytecode]
可以看到三种loader分别对应了三种不同文件的加载方式:
- 动态库:ExtensionFileLoader
- .py文件:SourceFileLoader
- .pyc文件:SourcelessFileLoader
SourceFileLoader
这里先来看下SourceFileLoader的实现,这个loader处理的是只存在.py文件时的逻辑过程,在导入时首先调用的是get_code函数获取文件对应的模块PyCodeObject对象。由于SourceFileLoader继承了SourceLoader,因此实际最终调用的函数是在SourceLoader中实现的,具体实现如下:
class SourceLoader(_LoaderBasics):
def get_code(self, fullname):
"""Concrete implementation of InspectLoader.get_code.
Reading of bytecode requires path_stats to be implemented. To write
bytecode, set_data must also be implemented.
"""
source_path = self.get_filename(fullname)
source_mtime = None
try:
bytecode_path = cache_from_source(source_path) # 根据文件名计算出实际的文件路径
except NotImplementedError:
bytecode_path = None
else:
try:
st = self.path_stats(source_path) # 一个字典结构,包含文件上次修改的时间或者源文件的大小,在这里默认会抛出IOError
except IOError:
pass
else:
# ...忽略代码
source_bytes = self.get_data(source_path) # 从文件路径中读取出文件内容
code_object = self.source_to_code(source_bytes, source_path) # 调用"compile"系统调函数,得到模块的 PyCodeObject 对象
_bootstrap._verbose_message('code object from {}', source_path)
if (not sys.dont_write_bytecode and bytecode_path is not None and
source_mtime is not None):
data = _code_to_bytecode(code_object, source_mtime,
len(source_bytes)) # 将PyCodeObject对象序列化为.pyc文件的内容
try:
self._cache_bytecode(source_path, bytecode_path, data) # 调用 set_data 函数,将.pyc文件内容持久化到磁盘,实际上调用的是底层文件IO接口
_bootstrap._verbose_message('wrote {!r}', bytecode_path)
except NotImplementedError:
pass
return code_object
我们来关注下_code_to_bytecode函数的实现,看它是如何把一个PyCodeObject对象序列化为.pyc文件内容的
def _code_to_bytecode(code, mtime=0, source_size=0):
"""Compile a code object into bytecode for writing out to a byte-compiled
file."""
data = bytearray(MAGIC_NUMBER) # magic值
data.extend(_w_long(mtime)) # 修改时间
data.extend(_w_long(source_size)) # 源文件大小
data.extend(marshal.dumps(code)) # PyCodeObject序列化
return data
关于marshal.dumps函数的实现,我们后面再展开讲解
SourcelessFileLoader
当存在.pyc文件时,在导入的过程中调用的就是SourcelessFileLoader中的get_code函数了,我们来看下其中的实现
class SourcelessFileLoader(FileLoader, _LoaderBasics):
"""Loader which handles sourceless file imports."""
def get_code(self, fullname):
path = self.get_filename(fullname)
data = self.get_data(path) #从文件路径中读取出文件内容
bytes_data = _validate_bytecode_header(data, name=fullname, path=path) #检查.pyc文件的合法性
return _compile_bytecode(bytes_data, name=fullname, bytecode_path=path)
校验的代码定义在_validate_bytecode_header中,我们来看下其中的实现
def _validate_bytecode_header(data, source_stats=None, name=None, path=None):
"""
data:从pyc文件中加载出来的字节串,即格式为b'xxx'
source_stats:源文件信息,当同时存在py文件时,则此处不为None
name:文件名
path:文件路径
"""
# data是字节串,即 b'xxxxx'
exc_details = {}
if name is not None:
exc_details['name'] = name
else:
# To prevent having to make all messages have a conditional name.
name = '<bytecode>'
if path is not None:
exc_details['path'] = path
magic = data[:4] # 读取magic值
raw_timestamp = data[4:8] # 读取上次修改时间
raw_size = data[8:12] # 读取源文件大小
if magic != MAGIC_NUMBER: # 当magic值对不上,则抛出异常
message = 'bad magic number in {!r}: {!r}'.format(name, magic)
_bootstrap._verbose_message('{}', message)
raise ImportError(message, **exc_details)
elif len(raw_timestamp) != 4: # 时间序列长度不对
message = 'reached EOF while reading timestamp in {!r}'.format(name)
_bootstrap._verbose_message('{}', message)
raise EOFError(message)
elif len(raw_size) != 4: # 源文件大小的长度不对
message = 'reached EOF while reading size of source in {!r}'.format(name)
_bootstrap._verbose_message('{}', message)
raise EOFError(message)
if source_stats is not None:
try:
source_mtime = int(source_stats['mtime'])
except KeyError:
pass
else:
if _r_long(raw_timestamp) != source_mtime: # 校验pyc文件时间和源文件修改时间
message = 'bytecode is stale for {!r}'.format(name)
_bootstrap._verbose_message('{}', message)
raise ImportError(message, **exc_details)
try:
source_size = source_stats['size'] & 0xFFFFFFFF
except KeyError:
pass
else:
if _r_long(raw_size) != source_size: # 校验源文件大小
raise ImportError('bytecode is stale for {!r}'.format(name),
**exc_details)
return data[12:] # 校验成功,则返回剩余的字节串
然后_compile_bytecode函数中对PyCodeObject对象进行反序列,具体实现如下:
def _compile_bytecode(data, name=None, bytecode_path=None, source_path=None):
"""Compile bytecode as returned by _validate_bytecode_header()."""
code = marshal.loads(data) # 调用 marshal.loads 函数进行反序列化
if isinstance(code, _code_type):
_bootstrap._verbose_message('code object from {!r}', bytecode_path)
if source_path is not None:
_imp._fix_co_filename(code, source_path)
return code
else:
raise ImportError('Non-code object in {!r}'.format(bytecode_path),
name=name, path=bytecode_path)
marshal.dumps
PyCodeObject序列化和反序列化的过程是相反的,我们来看下序列化的过程实现,这个过程对应的是marshal.dumps函数。
我们照例忽略一些中间细节,看到w_object函数的实现
static void
w_object(PyObject *v, WFILE *p)
{
/*
PyObject *v:目标对象,这里我们传入的是 PyCodeObject
WFILE *p:文件操作,作为写入缓存
*/
char flag = '\0';
p->depth++;
if (p->depth > MAX_MARSHAL_STACK_DEPTH) {
p->error = WFERR_NESTEDTOODEEP;
}
else if (v == NULL) {
w_byte(TYPE_NULL, p);
}
else if (v == Py_None) {
w_byte(TYPE_NONE, p);
}
else if (v == PyExc_StopIteration) {
w_byte(TYPE_STOPITER, p);
}
else if (v == Py_Ellipsis) {
w_byte(TYPE_ELLIPSIS, p);
}
else if (v == Py_False) {
w_byte(TYPE_FALSE, p);
}
else if (v == Py_True) {
w_byte(TYPE_TRUE, p);
}
else if (!w_ref(v, &flag, p)) // 复杂对象内容的处理
w_complex_object(v, flag, p);
p->depth--;
}
static void
w_complex_object(PyObject *v, char flag, WFILE *p)
{
// ... 忽略代码
else if (PyCode_Check(v)) { // 当为 PyCodeObject 对象类型
PyCodeObject *co = (PyCodeObject *)v;
W_TYPE(TYPE_CODE, p);
w_long(co->co_argcount, p);
w_long(co->co_kwonlyargcount, p);
w_long(co->co_nlocals, p);
w_long(co->co_stacksize, p);
w_long(co->co_flags, p);
w_object(co->co_code, p);
w_object(co->co_consts, p);
w_object(co->co_names, p);
w_object(co->co_varnames, p);
w_object(co->co_freevars, p);
w_object(co->co_cellvars, p);
w_object(co->co_filename, p);
w_object(co->co_name, p);
w_long(co->co_firstlineno, p);
w_object(co->co_lnotab, p);
}
// ... 忽略代码
}
上述代码中以w_xxx开头的函数负责将内容写入WFILE中的缓存,以w_long为例,我们看下背后的具体实现
static void
w_long(long x, WFILE *p)
{
w_byte((char)( x & 0xff), p);
w_byte((char)((x>> 8) & 0xff), p);
w_byte((char)((x>>16) & 0xff), p);
w_byte((char)((x>>24) & 0xff), p);
}
#define w_byte(c, p) do { \
if ((p)->ptr != (p)->end || w_reserve((p), 1)) \
*(p)->ptr++ = (c); \
} while(0)
可见数据的写入的主要是ptr所指向的内存缓冲区,回看WFILE的初始化,可以看到ptr实际指向内容与str字段有关,而str是一个PyBytesObject结构体
wf.str = PyBytes_FromStringAndSize((char *)NULL, 50); // PyBytesObject 对象
if (wf.str == NULL)
return NULL;
wf.ptr = wf.buf = PyBytes_AS_STRING((PyBytesObject *)wf.str);
查看PyBytesObject结构体的定义
typedef struct {
PyObject_VAR_HEAD
Py_hash_t ob_shash;
char ob_sval[1];
/* Invariants:
* ob_sval contains space for 'ob_size+1' elements.
* ob_sval[ob_size] == 0.
* ob_shash is the hash of the string or -1 if not computed yet.
*/
} PyBytesObject;
再看宏PyBytes_AS_STRING的定义
#define PyBytes_AS_STRING(op) (assert(PyBytes_Check(op)), \
(((PyBytesObject *)(op))->ob_sval))
可见ptr指向的实际就是PyBytesObject的ob_sval字段,该字段保存了序列化之后得到的字节数据
所以总结来说,PyCodeObject对象的序列化是依据字段的类型,同时依据字段是否定长,调用不同的封装函数写入WFILE缓存,对于不同类型字段的处理方式如下:
- 定长类型:
- 字段类型
- 字段内容
- 不定长类型:
- 字段类型
- 字段长度
- 字段内容
关于字符串的处理
在Python3中字符串有两种类型,一种是字节序列类型(b'xxx'),另一种则是字符类型。对于字节序列类型,处理起来比较简单:
else if (PyBytes_CheckExact(v)) {
W_TYPE(TYPE_STRING, p);
w_pstring(PyBytes_AS_STRING(v), PyBytes_GET_SIZE(v), p); #字节序列内容+长度
}
对于字符类型的处理就比较复杂。字符对象的底层实现根据不同的字符串长度,有不同的底层编码对象格式,如下表所示
| maxchar < 128 | maxchar < 256 | maxchar < 65536 | maxchar < MAX_UNICODE | |
|---|---|---|---|---|
| kind | PyUnicode_1BYTE_KIND | PyUnicode_1BYTE_KIND | PyUnicode_2BYTE_KIND | PyUnicode_4BYTE_KIND |
| ascii | 1 | 0 | 0 | 0 |
| 字符存储单元大小 | 1 | 1 | 2 | 4 |
| 底层结构体 | PyASCIIObject | PyCompactUnicodeObject | PyCompactUnicodeObject | PyCompactUnicodeObject |
在前面介绍字符串对象生成函数时有说过,代码会依据字符串的长度采用不同的编码对象格式,因此实际上在序列化字符类型时,也会根据不同的编码对象有不同的序列化方式
else if (PyUnicode_CheckExact(v)) {
if (p->version >= 4 && PyUnicode_IS_ASCII(v)) { // PyASCIIObject 编码对象
/*
ascii = 1
kind = PyUniCode_1BYTE_DATA
*/
int is_short = PyUnicode_GET_LENGTH(v) < 256; // 字符串长度小于256
if (is_short) {
if (PyUnicode_CHECK_INTERNED(v)) // 该字符串是否驻留
W_TYPE(TYPE_SHORT_ASCII_INTERNED, p);
else
W_TYPE(TYPE_SHORT_ASCII, p);
w_short_pstring((char *) PyUnicode_1BYTE_DATA(v),
PyUnicode_GET_LENGTH(v), p);
}
else { // 长度大于256
if (PyUnicode_CHECK_INTERNED(v)) // 该字符串是否驻留
W_TYPE(TYPE_ASCII_INTERNED, p);
else
W_TYPE(TYPE_ASCII, p);
w_pstring((char *) PyUnicode_1BYTE_DATA(v),
PyUnicode_GET_LENGTH(v), p);
}
}
else { // PyCompactUnicodeObject 编码对象
/*
ascii = 0
kind = PyUnicode_1BYTE_KIND、PyUnicode_2BYTE_KIND、PyUnicode_4BYTE_KIND
*/
PyObject *utf8;
utf8 = PyUnicode_AsEncodedString(v, "utf8", "surrogatepass");
if (utf8 == NULL) {
p->depth--;
p->error = WFERR_UNMARSHALLABLE;
return;
}
if (p->version >= 3 && PyUnicode_CHECK_INTERNED(v))
W_TYPE(TYPE_INTERNED, p);
else
W_TYPE(TYPE_UNICODE, p);
w_pstring(PyBytes_AS_STRING(utf8), PyBytes_GET_SIZE(utf8), p);
Py_DECREF(utf8);
}
}
最后,结合.pyc文件的前三种数据,最终存储在文件中的格式如下图所示:
注:long 代表 4 字节;byte 代表 1 字节;bytes 代表字节序列,由前置的 size 字段标识大小
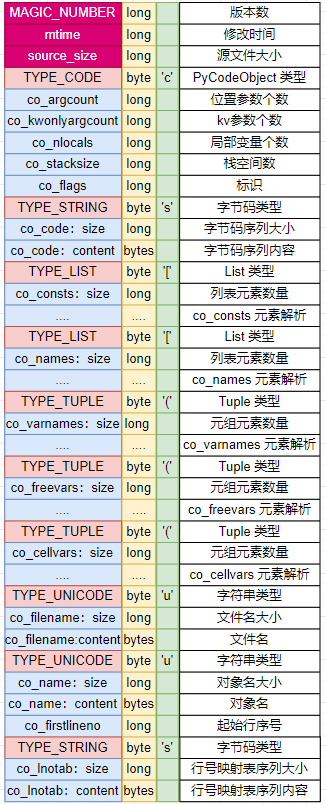
解析 .pyc 文件
从上面可以知道.pyc文件的文件内容,我们也可以直接使用相关函数进行解析读取,具体操作方式如下:
>>> f = open("D:\python project\__pycache__\code.cpython-36.pyc", "rb")
>>> magic = f.read(4)
>>> magic.hex()
'330d0d0a'
>>> mtime = f.read(4)
>>> mtime.hex()
'2dbcbe62'
>>> size = f.read(4)
>>> size.hex()
'40000000'
>>> code = marshal.load(f)
>>> dis.dis(code)
3 0 LOAD_CONST 0 (<code object Fun2 at 0x000002097FEB4660, file "D:\python project\code.py", line 3>)
2 LOAD_CONST 1 ('Fun2')
4 MAKE_FUNCTION 0
6 STORE_NAME 0 (Fun2)
8 LOAD_CONST 2 (None)
10 RETURN_VALUE