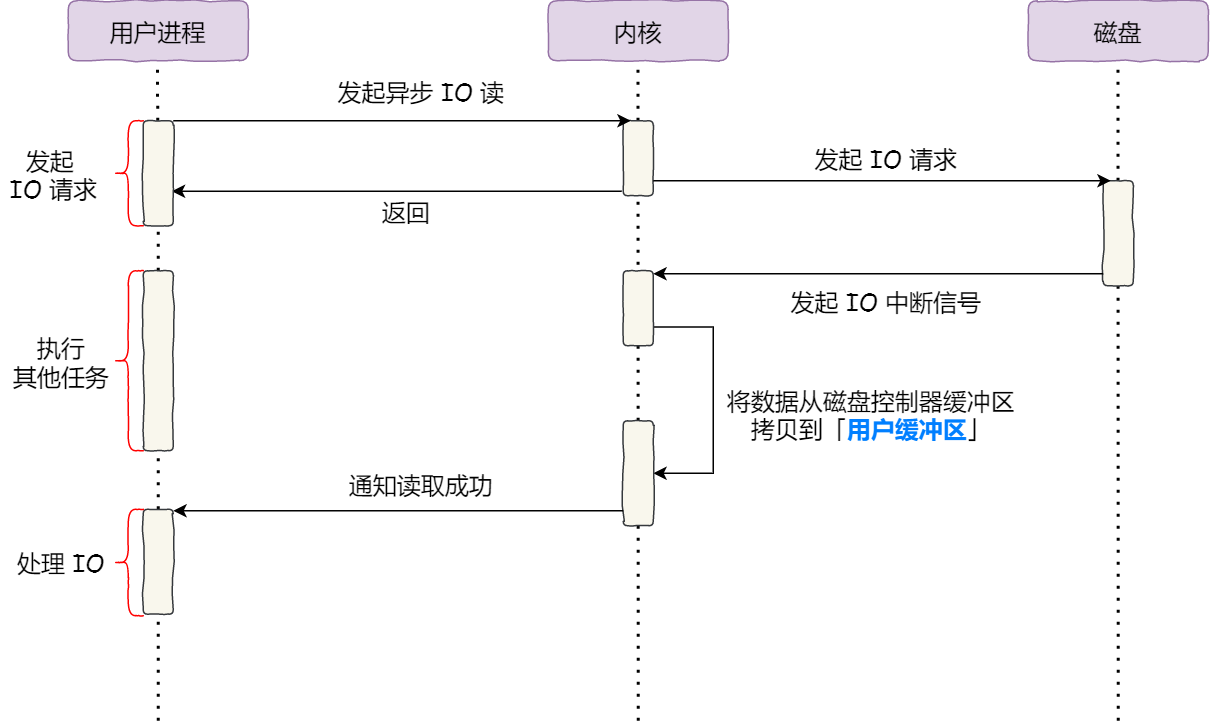
IO类型
linux 系统针对不同的场景,实现了以下几种 IO 类型:
-
Buffered IO(默认方式)
每次读取都需要经过 PageCache 缓存,这种方式的效率性能最高
-
Direct IO
读取不经过 PageCache 缓存,调用系统应用时需要指定 O_DIRECT 参数。因为没有经过内存缓存的缘故,虽然数据本身会直接落地到磁盘,但是一些文件的其他元数据还是会缓存在内存中,因此我们在使用 Direct IO 时,还需要配合使用
fsync进行强制文件写入磁盘。这种方式是应用在某些具有自己缓存方案的场景,如数据库自己设计了一套缓存方案,因此需要使用 Direct IO 来加速数据写入磁盘的速度
-
AIO
异步IO,linux 的 AIO 只能指定为 Direct IO 的形式,即不能经过 PageCache
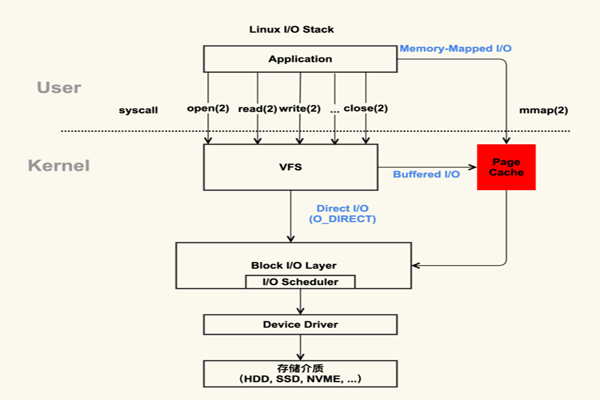
PageCache 技术
文件一般是存放在磁盘中的,当需要读取磁盘中的数据时,都需要先把磁盘中的数据读入内存,才能被 CPU 访问。为了避免每次读写文件时,都需要对硬盘进行读写操作,因此 linux 使用了PageCache(页缓存)机制对文件中的数据进行缓存。当 IO 的访问优先经过 PageCache 时,称为Buffered IO。而可以通过使用O_DIRECT参数,使访问不经过 PageCache,则称为Direct IO。
当我们使用mmap进行内存共享时,所映射的内核的内存空间也是位于 PageCache 中
页缓存读取
当 linux 系统在读取文件时,读取的流程如下:
- 进程调用
read函数发起文件读取请求,这会发生用户态到内核态的切换 - 从内核文件系统
VFS中找到文件的iNode信息,然后计算出要读取的具体的页 - 在
PageCache中查找对应页的缓存:- 如果页缓存命中,则直接返回文件内容;
- 如果没有对应的页缓存,则会产生一个缺页异常。这时系统会创建新的空的页缓存并从磁盘中读取文件内容,更新页缓存,再跳转到读
PageCache的流程
- 读取文件成功并返回
对于所有文件的读取,无论最初有没有命中页缓存,最终都会直接来源于页缓存
页缓存写入
当 linux 系统在写入文件时,写入的流程如下:
- 进程调用
write函数发起文件写入请求,这会发生用户态到内核态的切换 - 如果写请求不命中
PageCache,而且写入的 offset 或者数据的大小不与 4KB 对齐,则会先进行读 IO,将元数据加载到缓存中 - 从
PageCache中找到对应的文件页,将更新的内容写入到文件缓存,然后将其标记为dirty
脏页回写
linux 内核有单独的线程负责定时回写页缓存,在以下的三种情况下会触发回写:
- 空闲内存低于阈值,需要释放掉部分页缓存,此时如果页缓存为
dirty,则会写回磁盘,此时依据的是LRU规则 - 脏页在缓存的时间超过了阈值
- 用户进程主动调用
sync或fsync系统调用时,会强制进程立即回写- int sync():不等待写入结果;
- int fsync(int filedes):阻塞等待到对应的文件写入成功后才会返回
优缺点
PageCache 主要有以下两个优点:
- 缓存最近被访问的数据,从而避免了频繁读取同文件时的重复加载问题
- 预读功能,提升读取性能,默认最大是
32个Page(128KB)
但是,也具有以下的缺点:
- 额外占用了内存
- 当读取大文件时,会因为占用了整个 PageCache 而导致其他程序无法利用 PageCache 带来的缓存功能,反而降低了性能。因此对于大文件的读取,应该使用
Direct IO + 异步IO,在 nginx 中,就可使用该配置方式location /video/ { aio on; directio 1024m; }
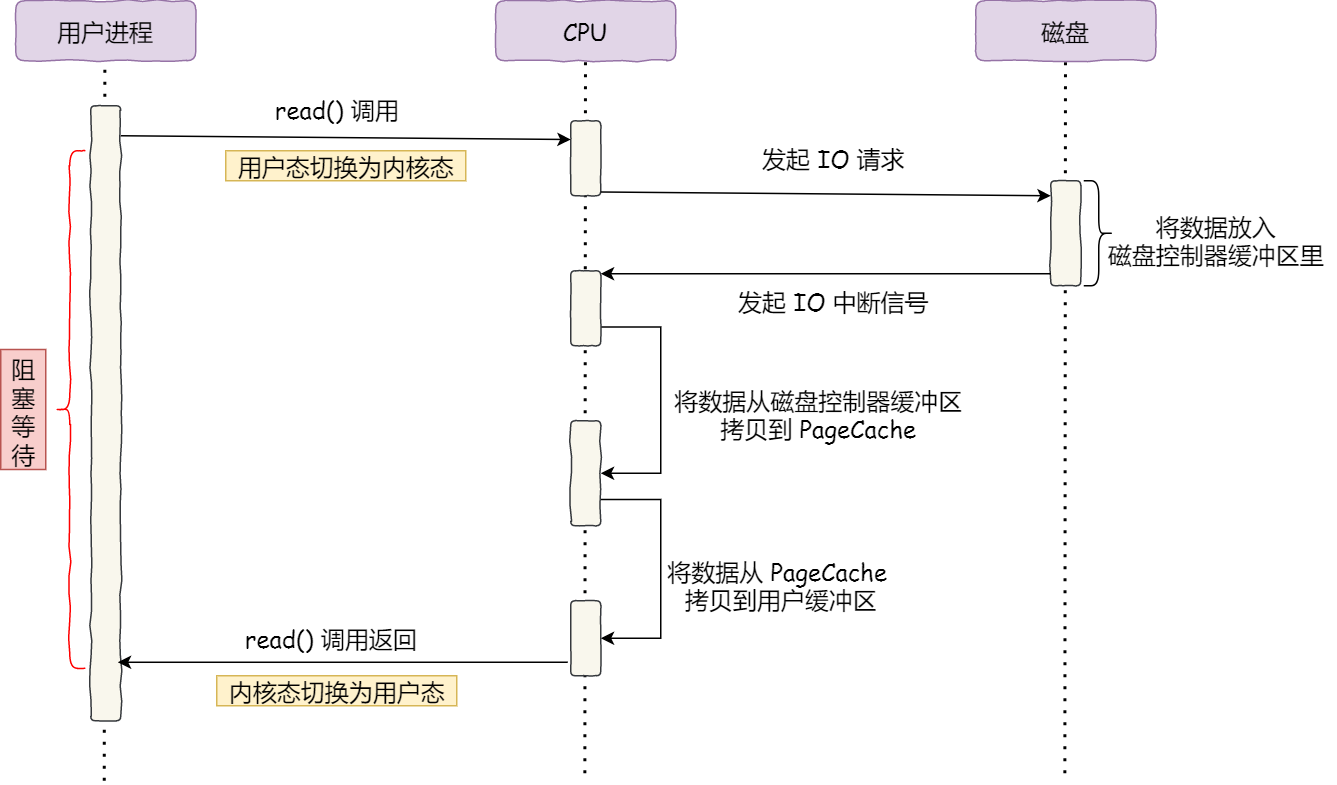
DMA 技术
在未有DMA技术之前,IO 读取的每个环节都需要 CPU 参与,这导致了总体性能是不高的
为了减轻 CPU 的压力,因此发明了DMA技术,即直接内存访问技术,在进行 IO 设备和内存数据传输时,数据的搬运都交给 DMA 控制器,而 CPU 不再需要参与数据的搬运。因此,现在的数据传输流程是这样的:
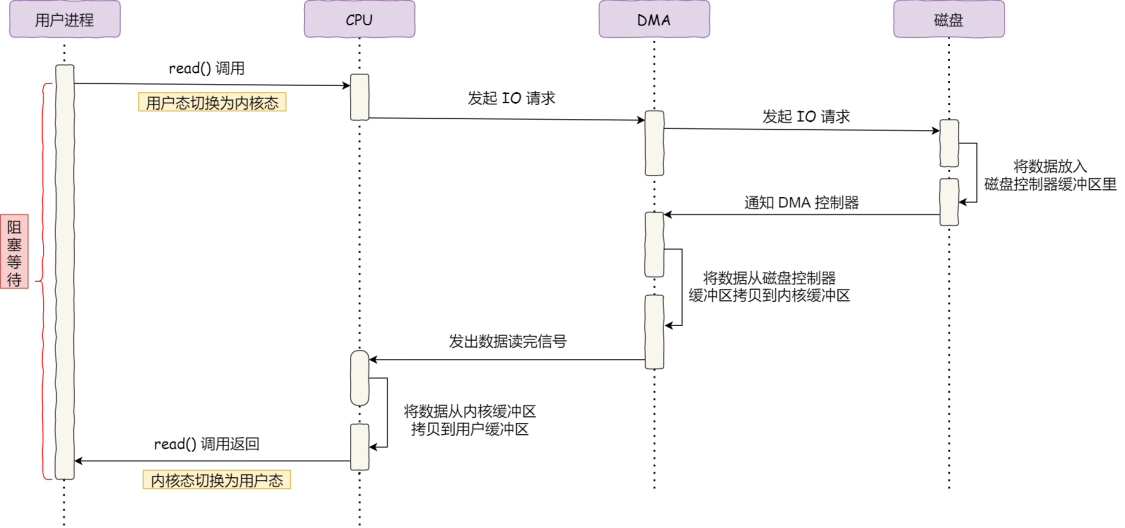
传统的文件传输
在使用零拷贝技术之前,尽管有了DMA技术,但是文件的读取还是有很大的开销,伴随着频繁的用户空间和内核空间切换,以及额外的数据复制。
一般我们使用以下两个系统调用:
read(file, tmp_buf, len);
write(socket, tmp_buf, len);
在这两个系统调用背后,文件数据的读取流程如图:
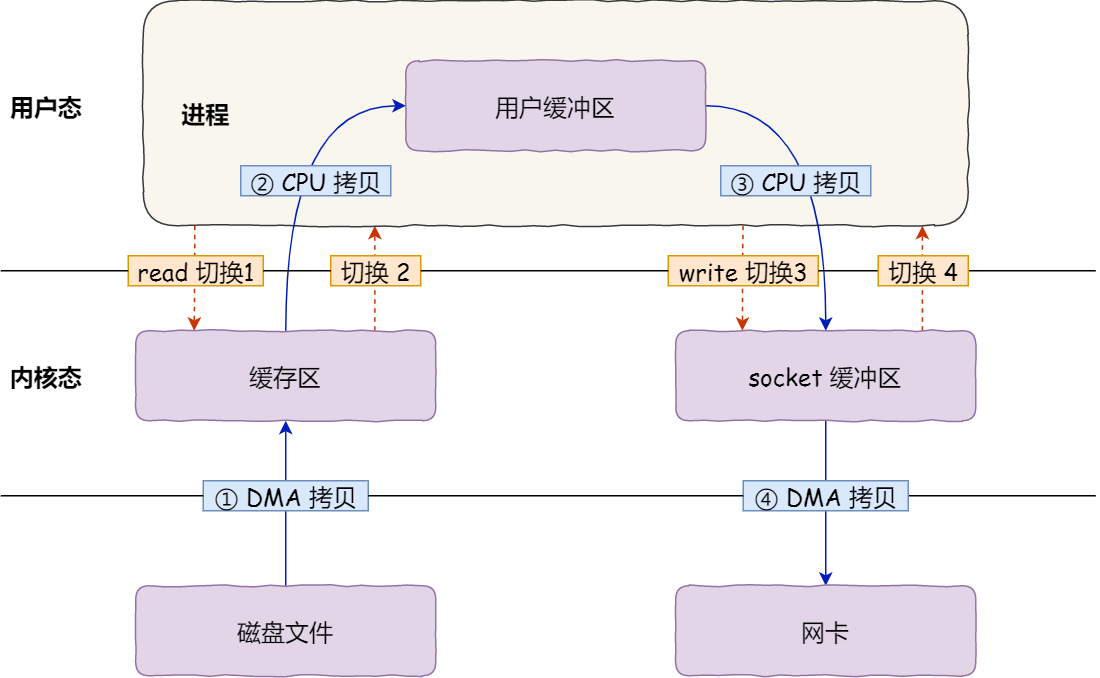
整个流程共发生了4次用户态和内核态的切换,当系统调用时都会先从用户态切换到内核态,而等内核完成处理之后,就又从内核态切换回用户态
在这个过程中,还发生了4次数据拷贝,其中两次是DMA拷贝,而另外的两次需要通过CPU拷贝
零拷贝技术
零拷贝技术通常有两种实现方式:
- mmap + write
- sendfile
mmap + write
当使用mmap替换 read 函数之后,调用的系统函数如下:
buf = mmap(file, len);
write(sockfd, buf, len);
mmap函数会直接把内核缓冲区的数据直接映射到用户空间,这样就可减少一次CPU拷贝
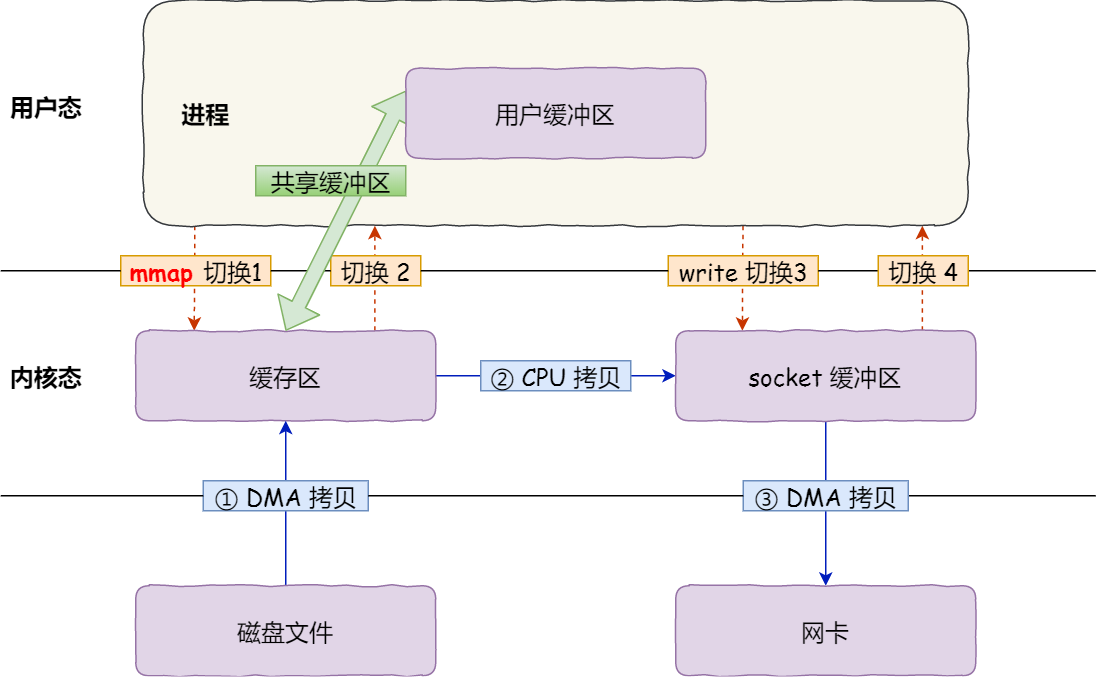
整个流程共发生了4次用户态和内核态的切换,以及3次数据拷贝
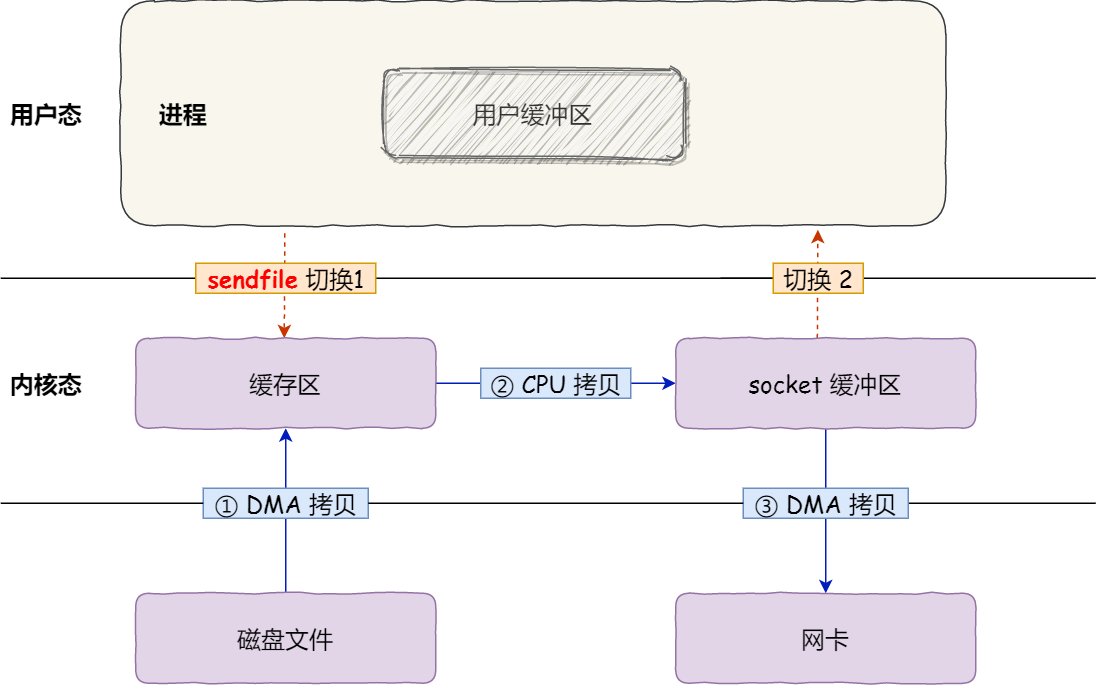
sendfile
在 linux 内核版本 2.1 以上,提供了sendfile系统函数,该函数签名如下:
#include <sys/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
/*
int out_fd:目的端的文件描述符
int in_fd:输入端的文件描述符
off_t *offset:输入端的文件偏移量
size_t count:目标复制数据的长度
return:
实际复制数据的长度
*/
通过该系统函数,即可减少一次系统函数的调用,从而减少了2次用户态和内核态的切换
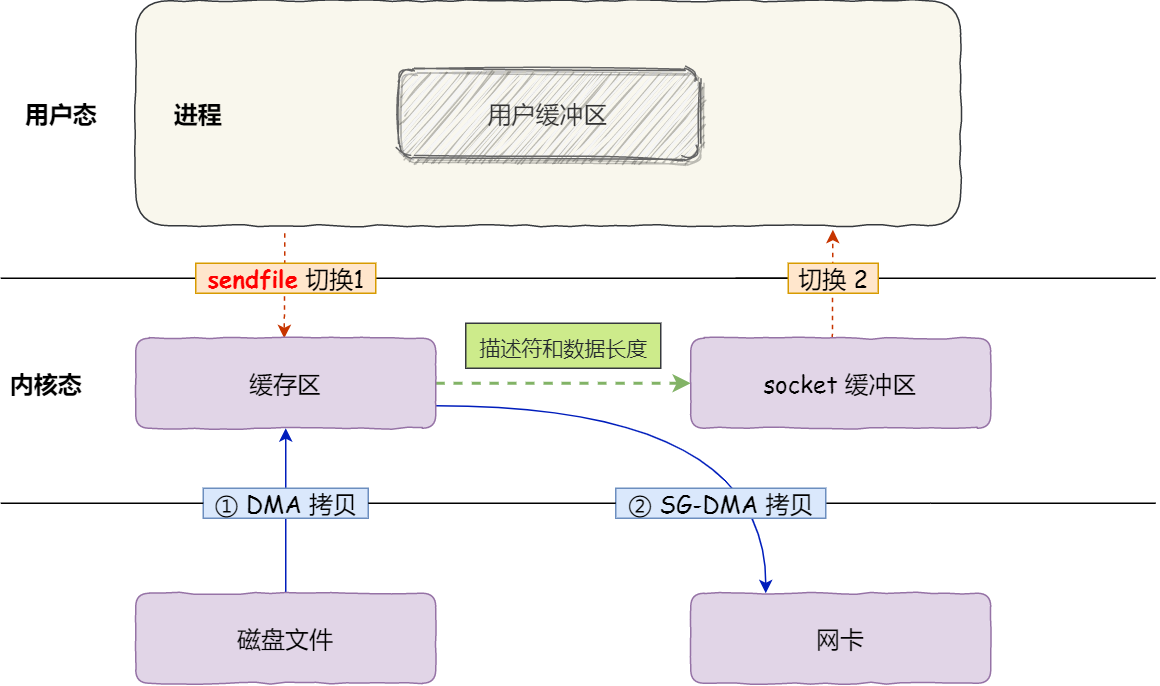
SG-DMA 技术
如果网卡本身支持SG-DMA技术,则可以减少通过 CPU 把内核缓冲区中的数据拷贝到 socket 缓冲区的过程
可通过以下命令,查看本机网卡是否支持 scatter-gather 技术:
rxsi@VM-20-9-debian:~$ /usr/sbin/ethtool -k eth0 | grep scatter-gather
scatter-gather: off
tx-scatter-gather: off [fixed]
tx-scatter-gather-fraglist: off [fixed]
从 linux 内核2.4版本开始起,在网卡支持SG-DMA技术下,sendfile系统调用即可减少1次CPU 拷贝
使用零拷贝的技术
RocketMQ
以 RMQ 的消息写入源码为例,可以看到其中的实现如下:
public PutMessageResult putMessage(final MessageExtBrokerInner msg) {
// ...省略部分代码
//获取内存映射文件句柄
MappedFile mappedFile = this.mappedFileQueue.getLastMappedFile();
//...省略部分代码
//重点来了,调用MappedFile.appendMessage方法将消息字节追加到共享内存中,由操作系统或者后台刷盘线程完成刷盘的动作
result = mappedFile.appendMessage(msg, this.appendMessageCallback);
//...省略部分代码
}
可见生产者在把数据持久化到磁盘时,使用的是mmap + write方式
再看 RMQ 的消息读取源码:
public GetMessageResult getMessage(final String group, final String topic, final int queueId, final long offset,
final int maxMsgNums,
final MessageFilter messageFilter) {
// ...省略部分代码
//根据 offset 找到对应的 ConsumeQueue 的 MappedFile
SelectMappedBufferResult bufferConsumeQueue = consumeQueue.getIndexBuffer(offset);
// ...省略部分代码
}
消费者的消息读取也主要依赖于mmap + write形式
kafka
当 Producer 生产者发送数据到 broker 时,采用mmap + write的形式,实现顺序的快速写入
当 Consumer 消费者从 boker 读取数据时,采用sendfile的形式,将磁盘文件读到系统内核后,直接通过 socket buffer 进行数据发送
nginx
nginx 可以通过配置开启零拷贝技术
http {
...
sendfile on
...
}
大文件传输
前面在 PageCache 一节介绍其缺点时,指出了在操作大文件时,会由于占用了 PageCache 而导致后续的操作无法利用到 PageCache 提供的缓存作用,因此可以使用 Direct IO 的方式绕过。
同时为了避免同步 IO 的阻塞问题,可以使用 AIO 进行异步处理,而 linux 的 AIO 只能使用 Direct IO 形式,因此对于大文件的操作,我们应该使用AIO + Direct IO的形式