背景
在分布式系统中一个不可避免的问题就是:数据一致性问题
对于一个状态的修改,如何使所有节点都能够读到相同的修改结果,做法一般有:
-
部署单数据处理节点:
这种处理方式一般是强制规定某个单节点作为数据处理节点,负责数据状态的收集,其他所有节点当需要获取数据状态时都与该节点进行交互。 这种方式一个显而易见的好处就是数据具有高度一致性,也易于编码实现,但是一个严重的问题就是当该节点宕机或者网络情况不佳时,将会导致其他节点无法与之成功交互,进而影响服务的运行。
-
集群化数据处理节点:
单点部署不具有高可用性,自然能够想到通过部署多个节点共同提供服务,提高系统的可用性,具体的实施方案有几种做法: - 数据均衡分不到多个几点(如以 hash 的方式),这样当某个节点故障时,只会有部分数据不可访问,一定程度减少了影响面; - 集群中的每一个节点都有完整的数据,这样当某个节点故障时,其他节点依然可以提供完整的服务数据,不会影响服务的运行;
比较这两个方案的差别,方案1相较于原始的单节点方案提高了一定的可用性,但也不是真正的高可用性系统设计。方案2可以提供完整的高可用性,但是如何保证多个节点之间的数据一致性是最大问题。
对于方案2所存在的数据一致性难点,一个朴素的解决方法是:设定一个主节点,当主节点接收到消息之后,把消息同步复制给其他集群节点,对于客户端的请求会直接阻塞到所有节点都写入成功再返回。但是这种实现方式显而易见的就是效率低,难以应用在高并发量的场景。共识算法就是为了能够高效的解决方案2所存在的难点问题而提出的。第一个被证明的共识算法是Paxos算法,但是算法晦涩难懂,代码实现上难度较大。而在2014年斯坦福大学教授提出的Raft算法较之Paxos算法具有相近的运行效率,但是更加容易理解,也更适用于系统工程开发。
Raft算法
网络上介绍Raft算法的文章很多,本文不会深入解释各协议的设计意图,仅适当描述功能实现过程中的思考点以及改进的方案
节点状态与转换
节点的三种状态
- follower:跟从者
- 节点启动时的初始状态,在启动时同时开启周期为
心跳超时时间的定时器,当超过时间未接收到 leader 心跳包,则转变身份为 candidate - 当节点处于任意状态而接收到其他节点
term(任期)大于本节点的任期时,自动切换为 follower 状态,且更新本节点的term信息 - 节点处于任意状态(实际上不可能是 leader 状态,因为同周期只会有一个 leader)收到相同
term的 leader 心跳 RPC,则说明选举出了新的 leader,本节点自动切换为 follower 状态
- 节点启动时的初始状态,在启动时同时开启周期为
- candidate:选举者
- 当节点状态处于 follower,且在设定的心跳超时时间内未收到 leader 的心跳包 RPC,则转变为 candidate,且把当前任期
term + 1,以保证在同一个任期中只会有一个 leader 节点被选举出 - 处于 candidate 的节点依然开启着周期为
心跳超时时间的定时器,当在周期内未选出新 leader,则进入新一轮选举 - 当收到过半的选举赞成票,则切换身份为 leader 身份
- 当节点状态处于 follower,且在设定的心跳超时时间内未收到 leader 的心跳包 RPC,则转变为 candidate,且把当前任期
- leader:领导者
- 负责接收和转发客户端消息,当消息在集群中达成共识之后反馈回给客户端
- 转变为 leader 的节点会停止周期为
心跳超时时间的定时器,而开启周期更短的心跳包定时器,定时向集群中其他节点发送心跳包 RPC
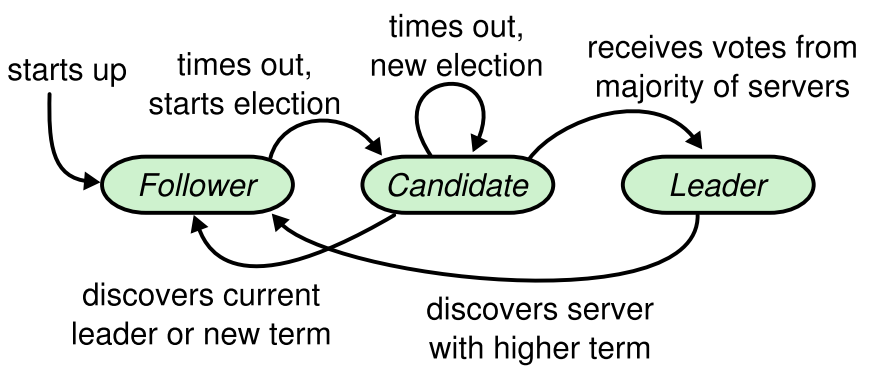
leader切换与心跳超时
在系统启动之初,所有节点都处于 follower 状态,必须经过一个心跳超时时间之后才能转变为 candidate 状态,因此心跳超时时间不能设定过长,否则会使得系统开启时陷入较长时间的不能工作状态。当然这个时间也不能过短,不然容易受短时间网络波动影响而频繁切换 leader 节点。目前默认的时间设定为20s,同时 leader 节点的 心跳包时间为5s
改进措施
原始论文中没有考虑以下两种情况:
- 系统出现网络分区,其他 follower 节点在网络分区期间选出了新的 leader 节点,同时旧的 leader 节点还存在(新旧 leader 节点处于不同的 term)。这样导致客户端发送给该旧 leader 节点的消息都会经过 RPC 超时时间之后才会返回失败结果,影响服务;
- leader 所在的网络出现故障,导致只能向外发出消息而无法接收消息,这种情况向外发出的消息会一直抑制其余节点开启新的选举,但是因为无法收到回复,因此无法在集群中对客户端消息达成共识,集群陷入无法工作状态
以上两种情况归根到底就是需要让 leader 节点具有自我感知能力,能够自主察觉出网络的异常情况,继而转变身份为 follower 状态。因此在 leader 节点向其他节点发送心跳包 RPC 时,同时也记录了上次接收到反馈的时间,这样当发现超过一半的节点没能在心跳超时时间内及时反馈时,leader 节点就可以主动切换为 follower 节点了。
Leader选举
当系统启动时,所有的节点都处于 follower 状态,当节点到达设定的心跳超时时间后转变为 candidate 状态。处于 candidate 状态的节点会向集群中其余节点发送 投票RPC,且开启周期为选举投票超时时间定时器,用以对未回复投票的节点定时重发。
RequestVote_RPC
请求参数有:
- candidate_term:本节点的任期
- candidate_id:本节点的ID
- last_log_index:本节点的最新日志的序号
- last_log_term:本节点的最新日志的任期号
响应参数有:
- term:被请求节点的任期
- vote_granted:是否同意投票给候选人
选举时机
当节点启动时,如果所有的节点都严格按照心跳超时时间的周期启动定时器,那么显而易见将会导致有多个节点同时切换为 candidate 状态,进而同时发出投票请求,导致选票被瓜分,最终无法达成选举赞成票超过一半的结果。当此轮投票选举没有任一个节点获得超过一半的赞成票时,当心跳超时时间的周期启动定时器到达时,开启新一轮的选举。
为了避免这种情况,在启动定时器时,需要加一定的随机参数,当前的随机时间为心跳超时时间 + rand(0, 5)
选举流程
投票发起方
- 将自身身份切换为 candidate
- 将当前任期 + 1
- 给自己投票
- 给集群中其他节点发送 RequestVote_RPC
- 开启选举超时定时器(在设置中定为 5 秒),当某个服未及时回复请求投票 RPC 时,定时重发 RequestVote_RPC
投票接收方
- 判断对方的 term 与本节点的 term:
- 当 candidate_term < cur_term:说明这条 RPC 是过时的,返回本节点的 cur_term 并投反对票
- 当 candidate_term > cur_term:本节点(不管当前处于什么状态)切换为 follower,并重置已投票节点信息,继续下面逻辑
- 检查已投票节点信息(注意从这里开始,candidate_term 与本节点的 term 必定相等)
- 如果本节点已经投过票,返回本节点的 term 并投反对票,因为在同一任期内只能投票一次。注意一点有可能节点会收到同一个 candidate 的同一个任期的投票 RPC,比如当网络出现延迟时,这里的处理方法可以是任一方的去重过滤
- 对比日志消息:
- 如果 candidate_log_term > cur_log_term 或(candidate_term == cur_log_term && candidate_log_index >= cur_log_index):说明在同任期下对方日志更新,可以投票给他。设置本节点的已投票信息为对方节点信息,返回本节点的 term 并投赞成票
- 否则对方日志不是最新的,返回本节点的 term 并投返回票,这确保了选举出的节点一定具有最新的日志
candidate 接收到投票反馈
- 如果接收到信息时本节点已经不是 candidate,忽略该消息
- 如果对应的 term 大于本节点的 term,本节点切换为 follower,因为集群已经开启了一轮新的选举
- 如果对方的 term 小于本节点的 term,忽略该消息,因为已经是过时的了
- 如果对方的 term 等于本节点的 term,且是赞成票,记录入已经投赞成票的节点列表中,并判断是否已经获得超过一半以上的赞成票,如果是则转变为 leader
成为 leader
当节点称为 leader 时,需要做的操作有:
- 停止周期为
心跳超时时间的定时器和周期为选举超时的定时器 - 开启周期为
心跳包的定时器,定时向所有 follower 节点发送心跳包 - 初始化两个map数据:
- next_index_map:以节点号为key,当前节点的日志长度+1为val:
该 map 的意义在于记录下一个应该发送给 follower 的日志信息。比方说当前的 leader 有10个日志,那么记录的其他 follower 节点的 next_index = 11,这意味着通过 AppendEntries_RPC 发送给客户端的第一个 pre日志将会是本节点的最新日志。当最新日志匹配不上时,再逐渐往前递减尝试匹配,直至匹配上。
- match_index_map:以节点号为key,val为0
该 map 的意义在于记录 leader 与 follower 当前已经匹配上的日志信息。通过该 map,leader 可以判断某个日志是否已经被超过一半的节点复制,进而对应响应的日志进行 commit,并 apply 到上层状态机
选举安全性
从上面的选举过程可知,一个节点成为 leader 的必要条件有:
- 具有最新的日志
- 最新的日志并不代表最长日志,而是代表已经达成共识的最长的日志。在集群运行的过程中可能出现,原节点1为 leader节点,并且接收了来自客户端的10小消息,转换为了10条日志信息,但是这10条日志并没有达成共识,节点1就因为网络问题失去了 leader 身份。此时如果集群中的其他节点选出了新的 leader 节点,那么节点1的日志属于
脏日志,在后续复制的过程中,会被删除。(因为日志没有达成共识,对于客户端的表现来说,就是消息超时了)
- 最新的日志并不代表最长日志,而是代表已经达成共识的最长的日志。在集群运行的过程中可能出现,原节点1为 leader节点,并且接收了来自客户端的10小消息,转换为了10条日志信息,但是这10条日志并没有达成共识,节点1就因为网络问题失去了 leader 身份。此时如果集群中的其他节点选出了新的 leader 节点,那么节点1的日志属于
- 获得超过一半的赞成票
- 一个节点在一个任期内只能给一个节点投赞成票,这保证了总赞成票一定和集群节点数相等,也就不可能出现一个任期选出两个 leader 的问题。(当然则建立在有对投票信息进行存库的前提下,后面有讲解到在不存库的情况下如果保证 leader 的唯一性)
- 每个节点都记录本轮投票给哪个节点,这个信息只有在任期+1的时候才能被重置
日志复制
日志格式
当主节点接收到客户端消息后,需要把当前消息存储在日志列表中,每个日志的结构包括:
- log_index:日志ID,严格递增,与日志列表的下标形成映射。因为有日志压缩功能,因此日志ID并不等于日志列表下标
- log_term:日志term,为主节点接收到该消息时正处于的任期
- command:命令消息,需要保存的命令信息由 Set / Del 操作,而 Get 操作是不需要转换为日志的
AppendEntries_RPC
该 RPC 既是日志复制的 RPC,也是心跳包的 RPC
请求参数有:
- leader_term:本节点的 term
- leader_id:本节点 ID
- pre_log_index:用以校验的日志 index
- pre_log_term:用以校验的日志 term
- entries:匹配的日志列表。在原论文中这里每次只发送一个 Entry
- commit_index:当前节点已经 commit 的日志 index
响应参数有:
- term:本节点的任期
- append_result:日志是否匹配成功,有四种结果码:
- False:pre日志匹配失败,需要往前回溯一个日志长度
- Quick:pre日志匹配失败,往前快速回溯至 follower_last_log_index + 1。原论文没有该状态
- True:复制成功
- Insnap:leader 发送过来的 pre日志已经在 follower 节点被压缩成快照了,往后前进一个日志。原论文没有该状态
- follower_last_log_index :节点的最新的日志 index
日志复制流程
日志复制发起方
- 客户端向 leader 节点发送 Set / Del 消息
- leader 接收到消息之后先追加到自己的日志列表中
- leader 发送 AppendEntries_RPC
日志复制接收方
- 判断 leader_term 与 cur_term 的关系
- leader_term < cur_term:证明对方 leader 已经过期,返回
False状态,及其他响应参数,leader 接收到消息之后会转换身份为 follower - leader_term > cur_term 或 本身节点正处于 candidate 或 首次接收到该新 leader 消息的 follower:转换身份为 follower 并更新 term 信息,同时保存 leader 信息
- leader_term < cur_term:证明对方 leader 已经过期,返回
- 重置周期为
心跳超时时间定时器,这里表现出的作用是抑制新选举周期的开启 - 判断 pre_log_index 和 pre_log_term 的关系
- pre_log_index > 本节点最新的日志 index:这说明本节点的日志还落后于 pre_log_index,通过返回
Quick状态,告知 leader 节点当前最长的日志,从而避免一个一个日志的回溯尝试 - pre_log_index < 本节点的快照 index:这说明该日志已经被压缩为快照,这种情况一般是由于 leader 在高并发的情况下连续发送了多条 pre_log_index 相同的消息。这消息应该要忽略,因此返回
Insnap状态 - pre_log_term != 本节点对应的 pre_log_index 位置的日志 term:这表示本节点有脏数据,未能形成匹配,因为返回
False状态
- pre_log_index > 本节点最新的日志 index:这说明本节点的日志还落后于 pre_log_index,通过返回
- 匹配成功,将 entries 中的日志添加到自己的日志中
- 根据 leader_commit_index,更新本节点的 commit_index
- 尝试 apply 新日志到状态机
- 尝试将日志转变为快照
日志复制发起方接收到反馈
- 如果接收到消息时本节点已经不是 leader 节点,则忽略该消息
- 如果对方的 term > 本节点 term,说明本节点是过期节点,转换为 follower 身份
- 更新与个节点的心跳包联通时间
- 判断复制结果:
- 结果为
False:更新 next_index 为 pre_log_index,即等价于往前回溯一个日志长度 - 结果为
Quick:更新 next_index 为对方节点 last_log_index + 1 - 结果为
Insnap:更新 next_index 为 pre_log_index + 2,即往后前进一个日志长度
上面计算出的新的 next_index 要与当前已有的 next_index 作比较,因为在高并发情况下,有可能会连续发送多条相同的 RPC,而导致接收到反馈时已经进入了新的状态,得到的反馈数据实际是旧数据,应直接忽略
- 结果为
- 结果为
True的情况下,更新 next_inde 与 match_index - 根据 match_index 计算新的 commit_index。当超过一半的节点都完成对日志的复制时,代表达成了共识,因此可以更新 commit_index
- 尝试 apply 新日志到状态机
- 尝试将日志转换为快照
- 如果对方日志还落后于本节点的日志进度,继续发起 AppendEntries_RPC 进行日志复制追赶
改进措施
在上文提到了几个新增的参数,下面解释下其意图:
- AppendEntries_RPC 中的 entries 参数和 Quick 参数
在原论文中,日志复制的形式是通过一个个日志的尝试匹配进行的,而且每一次都会携带完整的日志 Entry,而不管上一个 pre日志是否匹配上。这种效率并不高,因此修改为了只有当前一条 AppendEntries_RPC 的反馈为True时,下一条 AppendEntries_RPC 才会携带日志信息,且一次性最大发送500条日志 Entry,加速复制。判断的时机是在日志复制发起方接收到反馈的第9个步骤处。
快照压缩
在正常的服务运行中,日志会一直不停的增长(考虑的是以内存缓存所有的日志),但是在实际的项目工程中并不能接收这种情况,因此有了日志压缩功能。 对于一个有 Set / Del 操作的状态机来说,持续性的操作会导致日志一直的增长,但是状态机的数据增速会慢于日志的增长,此时快照压缩的优点就体现出来了。通过拷贝上层状态机当前的数据状态,然后把该时间节点之前的日志删除,就减少了内存的占用。 在实现快照的过程中有两个实现方案:
- 一种只能由 leader 节点压缩快照,而 follower 节点只能被动接收。这种情况在状态机数据少的时候没有多大的弊端,但是状态机数据大时,因为每次压缩日志 RPC 都需要把完整的快照发送给 follower,会耗时很久,因此不推荐这种方案
- 另外一种则是每个服自行进行快照压缩,这种做法效率更高,缺点是会出现不同的压缩进度,编码上需要注意的细节更多
在实现上最终使用的是第二种方案,需要的记录的信息有:
- snap_index:执行快照时,被压缩的最后一个日志的 index
- snap_term:执行快照时,被压缩的最后一个日志的 term
- snap_shot:当前的上层状态机的压缩数据,一般是把上层状态机的数据进行 copy + 压缩
因为有了日志压缩功能,因此日志的 index 并不与日志列表的下标相等,而是形成 log_index - snap_index = 下标的映射关系
快照压缩时机
作为 leader 节点,每次接收到 AppendEntries_RPC 反馈时,都需要检查 apply_index - snap_index >= 配置的快照压缩日志数。而作为 follower 节点,则是每次接收到 AppendEntries_RPC 时就判断是否快照压缩。因为这两个过程都有可能伴随着日志的增长和提交,进而使 apply_index 发生更新,因此需要判断是否需要进行快照压缩
快照压缩流程
- 复制压缩上层状态机数据
- 修改 snap_index = apply_index
- 修改 snap_term = apply_index 对应日志的 term
- 删除日志到 apply_index 日志对应的位置
在实践的过程中发现当数据量大时快照往往会非常大,因此做了一些措施尽量避免通过快照协议进行复制,具体措施见下文改进措施
InstallSnapshot_RPC
请求参数有:
- leader_term:本节点的任期
- leader_id:leader 节点编号(等价于本节点的编号)
- snap_index:快照 index
- snap_term:快照 term
- snapshot:快照信息,可能会很大,必要时需要进行分包处理
响应参数有:
- snap_result:快照复制结果
- follower_term:从节点任期
快照复制流程
快照复制发起方
- 当 leader 通过 AppendEntries_RPC 发送日志复制时,如果计算所要发送的 pre日志已经被本节点压缩进快照,则进入快照复制流程
- 发送 InstallSnapshot_RPC 给对应的 follower 节点
快照复制接收方
- 判断 leader_term 与 cur_term 的关系
- leader_term < cur_term:证明对方 leader 已经过期,返回
False状态,及其他响应参数,leader 接收到消息之后会转换身份为 follower - leader_term > cur_term 或 本身节点正处于 candidate 或 首次接收到该新 leader 消息的 follower:转换身份为 follower 并更新 term 信息,同时保存 leader 信息
- leader_term < cur_term:证明对方 leader 已经过期,返回
- 如果本节点 snap_index < leader_snap_index:复制 leader 的 snapshot,并更新
snpa_index、snap_term、apply_index、commit_index,并将 snapshot 写入覆盖上层状态机数据
快照复制发起方接收到反馈
- 如果接收到消息时本节点已经不是 leader 节点,忽略该消息
- 如果对方的 term > 本节点 term,说明本节点是过期节点,因此转换为 follower 节点
- 更新对应节点的 next_index
改进措施
从快照复制的过程中,可以看到每次的快照压缩都会对上层状态机的数据进行 copy + 压缩,然后通过 InstallSnapshot_RPC 发送给集群中的其他 follower 节点,并删除已压缩的日志。当快照数据很大时,InstallSnapshot_RPC 需要消耗很多时间,因此有了一种优化方案:尽量让节点自行压缩快照,避免通过 InstallSnapshot_RPC 的方式进行复制
分析触发快照压缩的时机可知,是根据最新状态的 apply_index 和上层状态机数据进行快照压缩的,而更新 apply_index 的时机是在 commit_index 发生更新时,commit_index 的更新则是当超过一半的节点对日志复制成功时。以一个3节点的 Raft 集群为例,当 leader 和其中一个 follower 对日志x完成复制之后就会更新 commit_index 和 apply_index,假设此时达到了触发快照压缩的条件,那么包括日志x及之前的日志就会被删除。对于另外一个复制较慢的节点来说,因为所要复制的日志在 leader 处已经被压缩为快照(很多情况下就复制差了几个日志),因此需要通过 InstallSnapshot_RPC 进行全量式更新复制。这种方式明显是低效的,应该要避免。
经过思考,有两种解决方案:
- 一种方案是上层状态机在保存数据时根据 log_index 划分不同的数据版本,这样在数据压缩时只压缩当前已在全部节点达成共识的 log_index 的数据版本,这样就避免了新日志在还未全部节点达成共识就被压缩的问题。但是这种实现方案需要上层状态机的配置设计,实现不方便,因此不考虑
- 当 leader 节点进行快照压缩时,根据 match_index 计算出当前复制最慢的节点的 log_index,在把最新的状态机数据压缩成快照后,只把日志删除到最慢服的 log_index 处。这样对于日志复制较慢的节点可以继续通过 AppendEntries_RPC 复制数据量更小的日志,而又保证了快照数据时最新的,因此最终采用的是该方案
分析上述方案2,由于改动之后 leader 的日志列表会残留已经被压缩为快照的旧日志,因此需要对前面的一些判断准则进行修改:
- 改动之前判断日志是否已经被压缩为快照的条件是根据
pre_log_index < snap_index,而修改之后要根据日志列表的第一个日志 index 进行计算pre_log_index < snap_index && pre_log_index < first_log_index - 触发快照压缩时,leader 根据 match_index 计算最小 log_index,每次只把日志删除到该 log_index 处,其余节点在发生快照压缩时仍根据 apply_index 清除日志。这么做的另外一个好处是如果一个 follower 节点之前是 leader 节点,且它的日志列表中含有残留的已压缩为快照的日志,那么经过一次快照压缩之后,这些日志就会被清除
- 在计算最小 log_index 时,为了避免某个结点长时间不上线,导致日志堆积过多,还需要根据 leader 与目标节点的心跳包联通时间进行计算。如果距离上次联通时间超时10分钟,且日志列表中已被压缩的日志超过了2倍设定的压缩日志长度,则应该忽略该节点提供的 log_index
存库
Raft 算法需要对必要的信息进行存库,需要存库的字段有:
- term:任期
- vote_for:本任期内投票给了哪个节点
- logs:日志列表
- snapshot:快照数据
- snap_index:最后被压缩进快照的 log_index
- snap_term:最后被压缩进快照的 log_term
- apply_index:已经 apply 到上层状态机的 log_index。原论文中未明确需要存库
改进措施
在原论文中,apply_index 是没有明确说明要存库的,但是在实际应用调试过程中,该参数还是需要进行存库处理的。 首先如果上层状态机的数据进行存库落地处理,那么 apply_index 是必须要存库的,否则当重启之后,则会无法判断具体哪些日志是已经进行了 apply。当然如果说依靠上层状态机的 **幂等性 **保证,即对于重复命令的执行会自动过滤,那么 apply_index 确实无需存库。
读写数据一致性问题
no-op包
在 Raft 中,新选出的 leader 是不能够确认集群中最新的 commit_index 的,设想一种情况是原 leader 在完成自己节点的 commit + applly 且反馈回客户端之后就宕机了。因为 follower 节点是通过 AppendEntries_RPC 获取 leader 节点的 commit_index 的,因此这存在滞后性,也就导致了新选出的 leader 节点的 commit 状态实际落后于集群系统的,因此客户端将会访问不到这些滞后的数据。
而根据 Raft 算法:节点只能 commit 自己当前任期的日志 的规则,新 leader 节点将会持续这种状态知道接收到新消息,进而被动的将之前滞后的消息提交。
为了解决这个问题,采用的是每当新选出 leader 节点,则规定该节点必须要主动提交一条no-op的日志,即只包含term和log_index的空日志,且该在该日志被 apply 成功之前,集群不能对外提供服务
主写主读
在 Raft 原文的设计中,主节点负责了数据的写入和读取,对于写操作需要在集群达到共识之后才能写入上层状态机,但是读操作则是不需要在集群中形成共识,可以理解返回。
这种方案会把读写压力都集中在 leader 节点上,如果数据量过大,将会造成单节点的压力过大,服务性能下降
改进措施
网络分区下 leader 读操作的数据一致性问题
当出现网络分区后,即某个时刻会出现不同任期的两个 leader 节点,虽然在上面的阐述中,已经使用了 leader 节点监控心跳超时数,在绝大部分心跳超时则自动转换为 follower 节点 的机制,一定程度上降低了网络分区的影响。但是当读操作读取的是旧 leader 节点的数据,那么就会造成数据不一致。
可用的解决方法是使读操作也在集群中形成共识之后再返回,保证当前客户端读取的 leader 节点必定是可用的,从而避免读取到旧数据的问题
主写从读模式
在正常运行的系统中,follower 节点的复制进度可能会落后于 leader 节点,如果直接在 follower 节点执行读操作就有可能读到脏数据,造成数据一致性问题
采用 **etcd 的 Linearizable Read **方案,当读请求打到 follower 节点之后,follower 节点会想 leader 节点请求当前 leader 节点的 commit_index,作为read_index(这里不能够采用 AppendEntries_RPC 下发的 commit_index 的原因在于并不能保证该 commit_index 是最新的,但是在读操作之后再去请求得到的 commit_index 必定是最新的)。当 follower 收到回复之后,对比本节点的 commit_index 和 read_index,只有当 commit_Index >= read_index之后才读取数据并返回给客户端
在 etcd 方案中,实际上是强制等待 follower 节点同步上 leader 进度之后再返回,虽然对比原始的 **主写主读 **方案来说,主节点的网络IO并没有降低,但是状态机的数据读取操作本身可能是一个复杂的操作,这部分就转移到 follower 节点上了,但是这也给读操作带来了一定的延迟
另外如果客户端可以记录自己修改的数据,对于读取自己刚修改的数据,只从 leader 节点读取,而对于非新修改数据或其他节点修改的数据则从 follower 节点读取,那么也可以一定程度上减少读操作的延迟