分布式事务的原则
在单机事务中,我们可以满足 ACID 特性。
- Atomic(原子性):InnoDb 中通过 undo-log 保证
- Consistency(一致性):是 AID 实现之后的结果,即为目的
- Isolation(隔离性):通过 MVCC 和锁机制实现,MVCC 处理的是并发读问题(转变为快照读),比单纯使用读写锁更为高效
- Durablity(持久性):通过 redo-log 保证
在分布式场景下的集群系统中我们只能满足 CAP 特性之中的两个。
- Avaliablity(可用性):集群一直处于可用的状态
- Consistency(一致性):指在集群系统中,每个节点的数据都是相同的
- Partition tolerance(分区容错性):系统在遇到网络分区时,依然能够对外提供服务
因为只能满足其中两个,一般的系统设计都是满足 CP,对于 A 则是通过各种途径保证了高可用性。
在均衡 CAP 中一致性和可用性时,有了 BASE 理论。
- Basically avaliable(基本可用):分布式系统在出现不可预知故障时候,允许损失部分可用性,比如响应时间变长(如设计 groute 路由时当节点不能访问则直接将请求打到数据库),只能访问部分核心功能
- Soft state(软状态):允许不同节点的数据副本存在一定延迟内的数据状态不一致(如 raft 日志复制过程中,允许少部分节点的日志是落后于 leader)
- Eventually consistent(最终一致性):经过一定时间后,所有节点数据可以达到一致性(如 raft 日志复制最终所有节点都会达成一致)
数据一致性的三个级别
- 强一致性:每个时刻任意节点的数据都是一致的,且与全局时钟顺序一致
- 顺序一致性:每个时刻任意节点的数据都是一致的,但是不要求与全局时钟顺序一致
- 最终一致性:不保证每个时刻任意节点的数据时一致的,但是经过一定的时间后能够达成一致
分布式事务方案
XA事务/2PC
2PC称为两阶段提交,保证了事务的强一致性
三个角色
- TM:事务管理器,全局唯一
- RM:资源管理器,每个节点都是一个独立的资源,如MySQL实例
- AP:应用程序,事务的发起者
两阶段执行
- 阶段一(prepare阶段):TM向所有的RM发送 prepare 指令,各RM开始执行事务,如果执行成功并停在 uncommitted 阶段,则返回yes,否则返回no。这里会将执行过程中的undo消息和redo消息写入日志,同时当前事务的prepare状态会持久化,以防节点在返回yes之后宕机而其他节点实际进行了commit,最终导致数据不一致
- 阶段二(commit阶段):TM收集所有的ACK之后如果全部ACK都为ok,那么下发commit指令,否则下发rollback指令。不管是commit还是rollback,当收到对应ack之后TM结束事务。
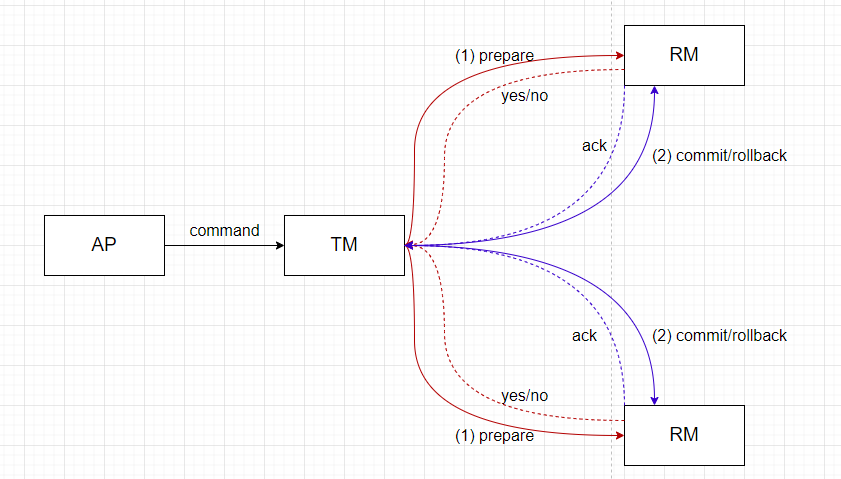
注:这里的rollback指的是事务未提交时的回滚,这点与TCC的rollback有本质上的不同
2PC存在的问题
- 2PC是blocking形式,当RM处于prepare阶段后,必须要阻塞等待下一步的指示。因为对于本RM来说,其他的RM的状态有可能是commit(本RM节点网络异常导致无法接收到TM的commit指令),也有可能是rollback(其他节点在prepare节点返回了非ok的ACK,而本RM与TM网络异常,未能收到rollback指令),因此本RM节点必须要阻塞等待。在设计上也**只对TM设定了超时机制,RM不存在超时机制 **
- 网络分区情况下,因为RM和TM的状态推进都要得到回复才会进行,因此只会造成blocking时间延长,而不会发生数据不一致
- 节点宕机情况下同时网络分区情况下,如TM向A节点下发rollback指令,节点A成功rollback之后,而后TM和节点A都宕机后且其余RM未收到rollback消息。新选出的TM会判断到其余节点处于uncommitted状态,而下发commit指令,最终造成节点A与其余RM的数据状态不一致(注:这个是网上的说法,但是如果在设计上TM必须要在全部节点都存活并回复结果后再下判断就不会有这种问题,因此2PC理论上是可以保证一致性的。)
应用场景
一般来说只应用在数据库层面,因为数据库支持XA协议。目前知道的应用场景是MySQL使用二阶段提交来保证binlog和redo log的一致性状态,这是建立在单机环境下的分布式事务,因此可以保证一致性。
3PC
3PC称为三阶段提交,是把2PC的第一阶段拆分为了两个阶段
三阶段执行
- 阶段一(CanCommit):TM向所有RM下发 CanCommit 指令,该指令目的是让各RM检查当前系统状态,是否有执行指令的条件。一般来说就是对资源进行加锁处理,但是相较于2PC在prepare阶段直接执行指令显得更为轻量,因为RM在这个阶段失败的可能性更高,因此越是轻量的操作,成本越低。TM和RM都有超时机制,当TM接收ACK超时后,会下发abort指令令各RM进行回滚。而RM在等待接收下一步指令超时后会直接进行回滚
- 阶段二(PreCommit):TM向所有RM下发 PreCommit 指令,该指令会使各RM指令事务,并停在uncommitted阶段,返回ACK,等待下一步指令,如果 RM 等待反馈超时,则直接对事务进行 commit
- 阶段三(DoCommit):TM向所有RM下发 DoCommit 指令,进行事务的提交
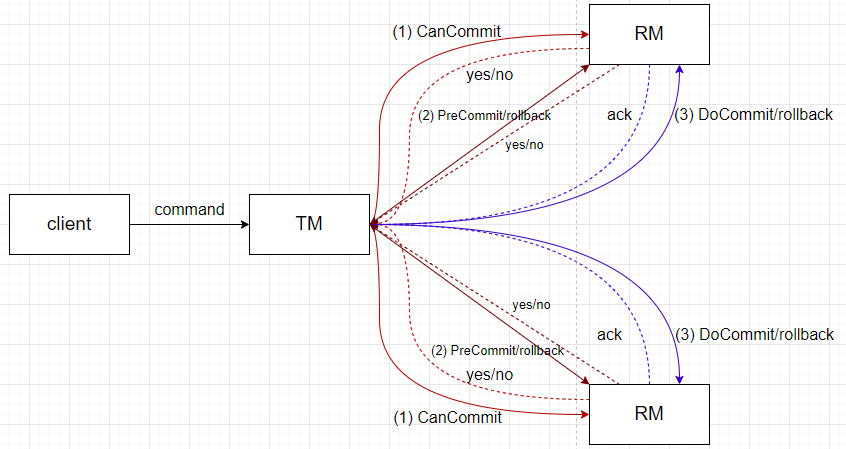
注:这里的rollback指的是事务未提交时的回滚,这点与TCC的rollback有本质上的不同
3PC存在的问题
- 3PC的设计本质上是为了避免2PC的blocking性质。为了解决这个问题引入了RM的超时机制,而为了 尽可能 的保证数据一致性,将2PC中的prepare阶段拆分为了两个阶段。当RM处于 CanCommit 阶段时,如果超时,则会选择结束事务,释放资源;当处于 PreCommit 阶段时,如果超时,则会选择提交事务。
- 3PC的运行是建立在不存在网络分区下的。如果存在网络分区情况,当RM处于CanCommit阶段时,其他RM节点可能处于PreCommit阶段,而处于PreCommit阶段的节点又会选择commit事务,这就造成了数据不一致问题。
- 当节点异常宕机之后,也会造成数据不一致问题
应用场景
不太了解具体应用场景,但是从上面分析来说,并不适用于跨网络环境,可能更多的还是用于单机环境下的分布式服务一致性。
TCC
TCC称为补偿事务,核心思想是针对每个操作都注册一个与其对应的确认和撤销操作 结构上和2PC相像,都是二阶段执行,但是2PC依赖的是底层数据库系统,commit/rollback 都是数据库系统自有的功能,因此要求RM必须要实现XA协议,而且2PC锁住的是底层资源,性能较差。而TCC则是业务层面实现的2PC,要求业务在使用TCC模式时必须实现Try()、Confirm()、Cancel()三个接口,不会锁定整个底层数据库资源,并发度高,实际的思想是先扣除,失败后再补偿的方式,因此保证了事务的最终一致性
二阶段执行
- 阶段一(Try):业务资源检查并预留相关资源(如冻结资金,但不扣款,因此查询还是有100原资金,只是当前可用的资金为70元,注意不会对资源加锁,因此实际上需要我们对数据库表格至少需要增加一个“冻结”字段),执行业务至“待确认”状态,然后返回执行结果yes/no。从设计上来说,处于Try阶段的业务不需要有超时处理,因为并没有对底层数据库资源进行锁定操作,等待TM的下一步操作命令即可。
- 阶段二(Confirm/Cancel):当try阶段所有服务都执行成功,则执行confirm,否则执行cancel。本阶段在业务逻辑上要保证成功,如果因为网络问题或其他故障,TM会一直重试直到返回成功
设计要点
幂等性
三个执行接口都要求有幂等性。TM可能会因为消息超时重发了任何一种命令,因此需要给事务加上全局唯一ID,利用该ID进行去重处理,以保证幂等性
空回滚
如果服务未接收到Try命令,而使TM判断事务执行失败而下发Cancel请求,那么服务在接收到该Cancel请求之后依然要执行成功并返回,即允许“空回滚”。
悬挂问题
如果在上面发生空回滚之后,Try命令又到达了服务,此时服务应该要能甄别出该事务ID已经已经执行了,如果已经执行了则不再执行Try命令
应用场景
TCC在实现的过程中要求服务系统实现Try/Confirm/Cancel三个接口,如果是第三方服务无法提供对应的三个接口,则无法应用TCC模式。因为采用的是“数据冻结”的方式,相较于2PC/3PC对资源层面的加锁,性能更高。在并发场景下,如果发生Cancel操作,重新“解冻”的数据不会造成数据隔离性问题。 适用于短事务,一致性要求度高的场景。
SAGA
saga是一种适用于长活事务的模式,通过将长事务分解成多个子事务集合,每个子事务都是一个保持数据一致性的真实事务。
执行流程
将长事务分解成多个子事务,根据恢复策略的不同,当执行不成功时,进行重试/回滚。这里的重试和回滚都是封装成事务的命令,这里就避免了侵入服务的代码,只需调用相关服务的接口即可。 因为每个子事务是独立的真实事务,如果发生回滚前有其余数据进行读取操作,那么本次事务相当于脏写,因此有数据隔离性问题。
以100元扣除30元为例:
- TCC中采用的是“资金冻结”的方式,在commit之前,读取到的结果将会是70元+冻结的30元。如果发生回滚,那么“解冻”的数据不会有数据隔离性问题
- SAGA采用的子事务方式,子事务提交之后,实际只剩下了70元,读取到的结果只有70元。如果发生回滚,那么会通过回滚事务将30元重新加到数据库中,则之前的子事务属于脏写。
恢复策略
向前恢复

对于执行不成功的子事务,会一直重试执行事务
向后恢复

对于执行不成功的子事务,按照已执行的子事务的你顺序进行回滚
应用场景
适用于无法改造接口的场景,有数据隔离性问题,适用于长事务场景,当是在无法执行时,更多的可能是需要人为进行干预