缓存策略
在实际工程项目中,为了提升系统的承载上限,降低数据库系统的并发访问量,一般我们会在应用和数据库系统中间增加一层缓存服务。当应用需要读取数据时先访问缓存服务,如果缓存服务存有目标数据,则可直接返回数据,否则则到数据库访问。
根据不同的更新策略,可以有以下几种方案:
- 读写穿透
- 异步缓存写入
- 旁路缓存
读写穿透(Read/Write Through Pattern)
此方案的重点在于对于数据的读写都要经过缓存服务,而后再由缓存服务去直接操作数据库的读取和写入
-
查询(Read Through):从缓存服务中读取数据,如果读取到则立即返回;如果数据不存在,则由缓存服务自行去数据库中加载数据,此时从应用发来的读操作将会进入阻塞状态,直到缓存服务读取数据成功再返回。
-
更新(Write Through):直接更新缓存服务中的数据,再由缓存服务去更新数据库数据,这两个操作要求在一个事务中完成。
从上面的查询和更新流程可知,应用层只需要和缓存服务直接交互,因此整体编码上会更加统一。这个方案可以保证数据的一致性,但是读写性能不高,适用于频繁读取相同数据,且对数据一致性要求高的场景。同时另外一个重点是要求缓存服务具有与数据库交互的能力,我们经常会把 Redis 设计成一个缓存中间件,但是 Redis 并不具有直接操作数据库的功能,因此如果使用 Redis 可能就无法使用该方案了。当然自己设计的缓存中间件就可以使用此方案。
异步缓存写入(Write Behind Pattern)
此方案的实现是通过直接操作缓存服务,而后再由缓存服务异步的更新数据库数据。因为是异步更新的缘故,因此对于缓存服务中的数据需要有额外的标记,至少需要有dirty和not-dirty的状态,用以表示该缓存数据是否经过了更新而还未更新到数据库。
-
查询:先从缓存服务中读取数据,如果读取到数据则立即返回;如果数据不存在,则由缓存服务从数据库中加载数据,写入存储服务后再返回,此时数据的标记是
not-dirty -
更新:直接更新缓存服务的数据,并标记为
dirty,后由缓存服务定时将dirty状态的数据写回到数据库中,再修改状态为not-dirty。
本质上是 Read/Write Througth Pattern 的异步实现版本,数据不是强一致性的,但是并发性能高,同时对于同份数据的操作修改可以合并到一次IO中,减少了不必要的IO开支。适用于一些经常变化,但是对数据一致性要求不高的场景,如浏览量、点赞量等
旁路缓存(Cache Aside Pattern)
此方案的实现规则要求应用可以同时操作缓存服务和数据库的读写,因此编码上会稍显复杂
-
查询:应用先从缓存服务中读取数据,如果读取到则立即返回;如果数据不存在,则应用再去数据库中查询,读取到数据之后再写入到缓存服务中
-
更新:应用直接更新数据库,更新成功后再去删掉缓存服务的数据
在更新的规则中,要求是先更新数据库再删除缓存服务的数据,下面列举当不这样实现时,会存在的异常问题。(注意下面的分析不包含意外宕机的问题)
- 方式一:先删除缓存,再更新数据库
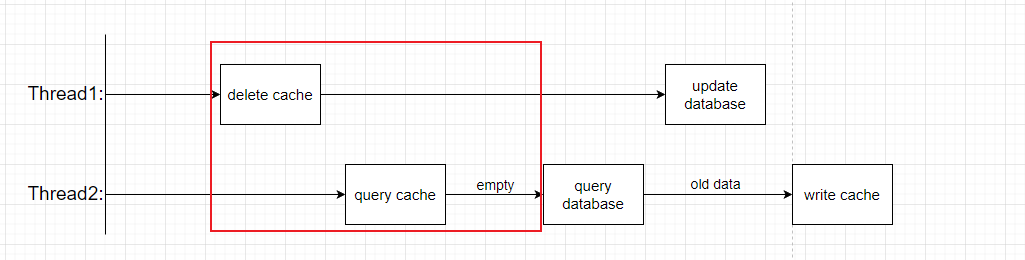
在上面的示例中,线程1先是删除了缓存,此时线程2进行了读缓存的操作,由于该缓存已被删除因此又去读取数据库的数据,此时读取到的是旧的数据。而后线程1完成对数据的更新,但是线程2仍是会把旧的数据写回到缓存服务中。
由于缓存服务一般是基于内存的读取,因此 delete / query cache的速度基本是一致的,即只要线程2在红圈中的网络速度快于线程1,就会造成脏数据问题,因此出现脏数据的概率大。
- 方式二:先更新数据库,再更新缓存
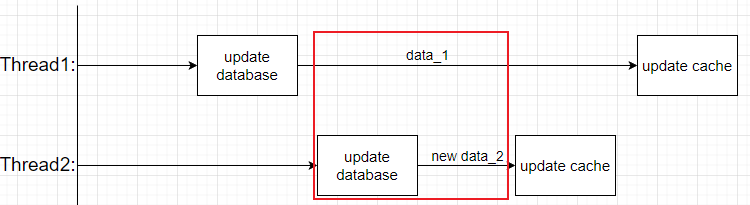
当线程1完成对数据的更新之后,线程2也对数据进行了更新,由于线程2的网络更优,因此先于线程1对缓存进行了更新,最后线程1再把已经数据旧数据的data_1写入到缓存服务中,造成缓存服务缓存了脏数据。
要出现脏数据问题,线程2要在红圈中的网络速度快于线程1,对于线程2来说,这包含了一个对数据库的写操作的耗时。如果对数据库的写操作本身较慢,那么出现脏数据的几率是较低的,而如果数据库本身IO状态良好,则出现脏数据的可能性就增大了。这个方案的最大问题在于如果存在了脏数据,由于没有额外的修正手段,赞数据会一直存在于缓存服务中,同时在首次读取数据时(查询缓存结果必定为空)也存在下面方式三中举例可能出现的异常问题。因此总体上不推荐。
- 方式三:先更新数据库,再删除缓存
此方案是最为推荐的方案。但是并不意味着就不会出现脏数据问题,在高并发的环境下,依然是有可能出现脏数据问题的。
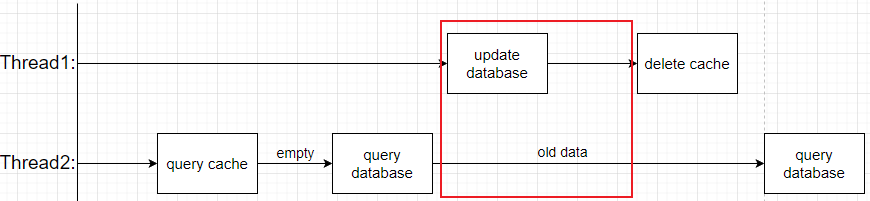
当线程1在更新数据库数据之前,如果线程2由于读取不到缓存数据而从数据库中读取了旧的数据,而后线程1完成对数据库数据的更新且删除了缓存服务的数据,线程2再把旧数据写回到缓存服务中,此时就造成了脏数据问题。
要出现脏数据问题,线程1要在红圈中的网络速度快于线程2,这也包含了一个数据库的写操作,具体情况如上述方式二中的分析。但是相较于方式二没有并发写的问题,因此总体更优。
延时双删方案
在旁路缓存的实现方案中,我们可以知道依然存在一定概率的数据不一致情况,因此有了延时双删方案,通过该方案可以进一步降低出现脏数据的概率
具体的实现步骤如下:
- 先删除缓存服务中的缓存数据
- 再更新数据库数据
- 休眠N时间(根据业务决定)
- 再次删除缓存
先删除缓存数据的原因在于第二次的删除是一个延时的删除,如果不先删除,则在延后删除触发之前的所有读操作将会读取到脏数据。但是注意,如果某个读操作在第一次删除之后,写数据之前发生的,则依然会读取到脏数据,并可能把脏数据写入到缓存服务中,该脏数据就需要依赖于第二次的延时删除了。
至于需要休眠多久时间,则需要根据实际业务决定,目标是避免图三红圈中的情况。
延时双删 + 缓存超时 + 消息队列
尽管使用了延时双删方案,但是仍然存在数据不一致的可能,例如当图三中红圈情况在经过延时之后依然发生了,则缓存服务的数据会长时间保持与数据库的数据不一致。因此需要引入**缓存超时**的设计,强制限定缓存服务中数据的有效期,这个有效期也需要根据实际业务而定。
使用延时双删 + 缓存超时,理论上最差情况是缓存过期时间内的数据不一致。
最后,对于删除缓存可能失败的情况,可以使用监听数据库 binlog 的方式,当发现删除操作时,首先尝试删除缓存,如果删除失败,则将删除消息存入消息队列,再由消息队列进行重试。
缓存问题
缓存雪崩
指的是短时间内,有大量的缓存过期,而导致大量的请求打到了数据库,从而对数据库造成巨大的压力
解决方法
-
随机过期时间 思路:在设置过期时间时,随机增加一定的偏移量
优点:实现简单
缺点:数据过期在一定范围内不可控,对于有精确时间控制的数据来说不可用
-
加锁排队 思路:当查询不到缓存时,对请求的
key加锁,只允许一个线程去数据库中查询优点:保证同一个 key 只有一个线程打到数据库,不会有大并发问题
缺点:降低了系统的反应性能
-
设置二级缓存 思路:设置本地缓存为一级缓存,Redis作为二级缓存,最后才是数据库
优点:性能高
缺点:设计复杂,需要同时考虑两个缓存的更新问题,编码困难
缓存击穿
指的是所要访问的数据在缓存和数据库中都不存在,是一次无效的访问,进而每次访问都需要查询数据库。
解决方法
-
使用布隆过滤器 思路:节点启动时,将数据库数据hash到
bitmap中,每次查询之前先使用布隆过滤器过滤掉一定不存在的数据优点:性能高
缺点:布隆过滤器设置完成之后在本次运行中,只能填入新数据而不能删除数据,如有大量数据的删除,那么布隆过滤器起到的作用较小很多了。另外,布隆过滤器不能直接扩容,当需要扩容时,应该启用新的布隆过滤器,负责填入新数据,而新旧布隆过滤器组成集群,当数据访问时同时访问集群中的所有布隆过滤器。
-
空对象缓存
缓存穿透
指的是某个热点数据失效,导致大量访问打到数据库
解决方法
-
加锁排队
-
设置永不过期 思路:把热点数据的过期设置设置为永不过期
优点:保证了访问热点数据时的性能
缺点:占用内存空间,且需要对热点数据有评估方案
缓存优化
缓存预热
指的是节点启动时预先把热点数据加载到缓存中,可以提升系统性能,这需要对系统数据有一定的评估能力