- 插入缓冲(insert buffer,提升性能)
- 两次写(double write,提升可靠性)
- 自适应哈希索引(提升性能)
- 异步IO(Asynchronous IO,提升性能)
- 刷新邻接页(Flush Neighot Page,提升性能)
插入缓冲(insert buffer,提升性能)
当索引是聚集索引时(主键索引),通常如果我们使用自增值作为主键,在插入时按照主键递增的顺序进行插入,那么是不需要磁盘的随机读取的,这种方式具有高效率。
CREATE TABLE t {
a INT AUTO_INCREMENT,
b VARCHAR(30),
PRIMARY KEY(a),
KEY(b)
};
根据这个特性,我们应该优先使用自增值作为主键,而如果使用的是非自增值作为主键,那么在插入时依然造成随机读取,使总体性能大大降低
对于非聚集索引,大部分索引值有随机性,因此必定会造成大量的随机读(页分裂和B+树节点自旋等)。为了进一步提升操作非聚集索引的性能效率,Innod db 设计了insert buffer机制,对于满足条件的非聚集索引的插入或者更新,不是每一次都直接插入到索引页中,而是先判断是否在缓冲池中,若在,则直接插入;若不在,则先放入到一个 insert buffer 对象中,再以一定的频率和情况进行 insert buffer 和辅助索引叶子节点的合并。
非聚集索引可使用insert buffer 的条件
- 索引是辅助索引
- 索引不是唯一的(即定义该字段时不能是 unique,因为如果是唯一的,那么引擎还需要在插入时进行扫描判断是否与已有索引相同,也就没有使用 insert buffer 的意义了)
PS:现在升级为了change buffer,可以对insert、update、delete同时缓存,分为insert buffer、purge buffer、delete buffer
内部实现
内部结构是一棵B+树,且全局唯一,放在共享表空间,默认是 ibdata1 中。
非叶子节点结构
对于应用于 insert buffer 的 B+ 树的非叶子节点结构实现如下:
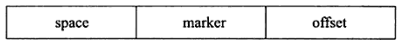
- space:对应着表空间id(每个表有唯一的space id),4字节
- marker:用以区分新老版本,1字节
- offset:表示当前索引页在原有表中的偏移量,4字节
所以一个非聚集索引是根据(sapce, offset)去确定的
叶子节点结构
相较于非叶子节点,增加了 metadata 结构和插入数据,结构如下:

metadata 字段的前两个字节存储的是插入该(space, offset)索引页的顺序,所以一条记录是根据(space, offset, counter)去确定的
ibuf bitmap
ibuf bitmap 存在于每一个 ibd 文件中(ibd文件存储的是表数据和索引数据,一个表对应一个ibd文件),每隔16384个页(innodb中一个页是16KB,因此16384*16/1024= 256MB)有一个 ibuf bitmap,且每个 page 占 4bits,用以标识当前辅助索引页是否被加载到了 insert buffer 中
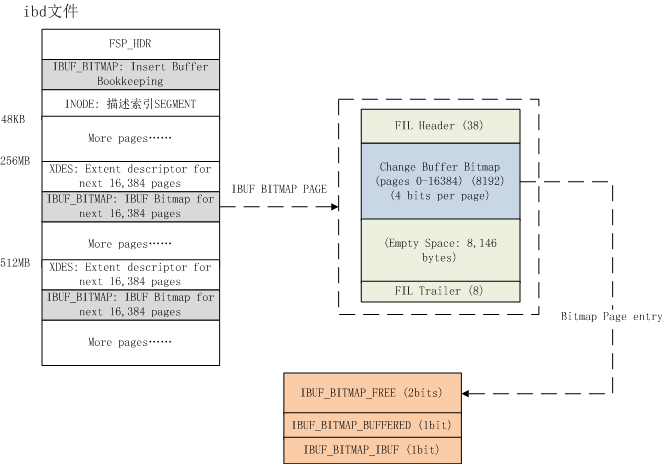
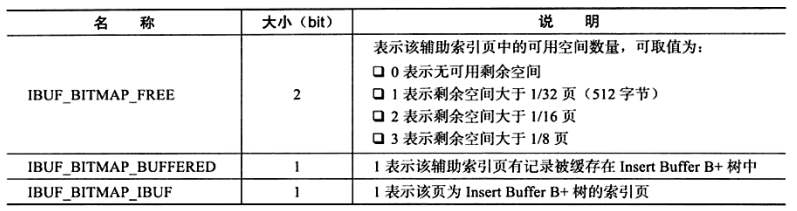
4bits的数据代表的意义如下:
merge insert buffer
将 insert buffer 的数据合并到磁盘的时机为:
-
辅助索引页被读取时
即当执行了 select 操作时,会根据
ibuf bitmap判断该页是否在 insert buffer 有缓存,当有缓存时,会一次性 merge 回写到原有的索引页中 -
ibuf bitmap 追踪到该辅助索引页已无可用空间时
当检测到剩余的页空间小于 1/32 页时(由 4bits 数据中的前两位决定),会强制触发一次 select 操作,即利用上面的规则引发一次 merge
-
master thread
定时的 merge insert buffer
两次写(double write,提升可靠性)
MySQL采用 WAL(Write Ahead Log)机制(先顺序写磁盘中的日志文件,再随机写磁盘中的数据页) 实现了在脏页写回前如果断电的情况下,能够进行重执行或回滚(依赖于 Redo Log 和 Undo Log,当然这两个日志也提供了事务执行失败后的回滚功能)。 doublewrite 解决的则是脏页写回中发生宕机情况如何进行恢复的情况,而不能只依赖于 WAL 的原因在于已经执行的操作会破坏掉原有的磁盘空间,而 Redo Log 记录的是偏移量状态信息,因此此时是无法发挥作用的。
内部实现
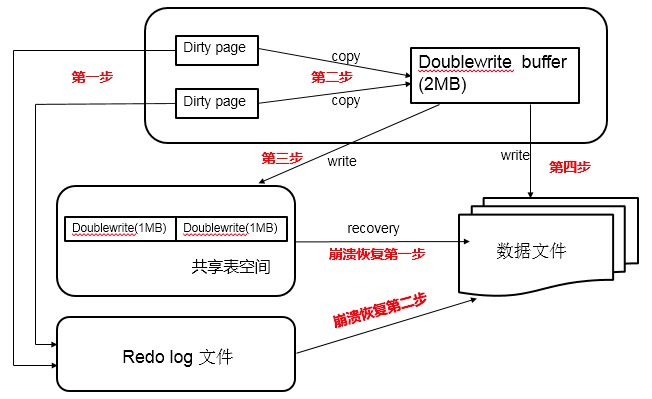
由两部分组成:
- 内存中的 doublewrite buffer,大小为2MB
- 共享表空间中连续的128个页,大小同样为2MB
执行过程
当脏页需要写回磁盘时,会先通过 memcpy 函数复制到内存中的 doublewrite buffer,然后通过再分两次,每次 1MB 顺序写入共享表空间中的 doublewrite 磁盘空间,这个过程写的是连续的磁盘空间,即顺序写,因此开销不大。当成功写入到共享表空间的 doublewrite 磁盘空间后,再把内存中的 doublewrite buffer 中的数据写回到各个表空间中(.ibd文件),也就是说进行了两次写盘操作。如果此时发生宕机,那么会从共享表空间中的 doublewrite 恢复。
小结
redo log 针对的是事务完成并返回给客户端结果,但此时脏页还存留在内存中(此时 redo log 已经写好了),如果服务进程意外宕机,此时磁盘结构还未被破坏,那么服务重启之后就会从 redo log 中恢复数据。
我们要区分宕机的各种情况,进程宕机时如果正处于磁盘IO,那么此时进程是处于不可中断状态的D状态,即无法使用 kill 指令杀死进程,这也就保证了如果脏页回写已经开始,那么就会持续到写完。如果脏页还没开始写进程就宕机了,那么就等重启后通过 redo log 恢复。如果连 redo log 都没有写完,那么很明显本身事务就没有完成,此时忽略这个事务事件即可。这就是为何我们称 redo log 是持久化的实现手段,绝大部分场景也是通过这个方式恢复即可。
另一种极端情况是突然断电了,那么就可能出现磁盘写入到一半的情况(partial page write),此时磁盘空间已经被破坏了,已经无法通过 redo log 进行数据恢复,因为 redo log 属于物理日志,即记录的内容是对数据页的物理操作:对 xxx 表空间中的 xxx 数据页的 xxx 偏移量的地方的值做了yyy更新。
这时候就需要 doublewrite 机制了,通过 doublewrite 记录的脏页直接覆盖被损坏的磁盘数据,即可恢复数据,此过程不需要 redo log。而如果 doublewrite 写入过程中宕机了,那么证明磁盘空间还完好,直接通过 redo log 进行恢复即可。
前面已经论证了为何在有 redo log 的情况下还需要 doublewrite,那么反过来是否可以只用 doublewrite 而弃用 redo log 呢?答案当然是否定的,redo log 的日志写入伴随着事务执行的过程中,针对的是单条语句对磁盘空间的物理作用,而 doublewrite 的生成是在脏页准备回写时,想象一下如果没有 redo log,那么就可能出现执行了事务产生了脏页,也回复客户端事务执行成功了,在写回到 doublewrite 之前宕机了,那么就会丢失数据,而如果等写回 doublewrite 之后再返回给客户端结果则又是一种低效的方式。因此 redo log 和 doublewrite 都是必须的。
自适应哈希索引(提升性能)
通常一个 B+ 树会设计为3、4层的结构,每一层代表了一次IO,因此至少需要3、4次 IO 才能读取到值。innodb 会根据查询频率,自动对热点数据建立 hash 索引,条件如下:
- 该模式查询了100次
- 页通过该模式访问了N次,N = 页中记录数/16
hash索引只适用于等值查询,对于范围查询不会建立hash索引
异步IO(Asynchronous IO,提升性能)
AIO的优势:
- 用户无需等待前一个 IO 回复之后再请求下一个 IO
- AIO 可以合并多个关联 IO 为一个 IO 请求,提升效率
刷新邻接页(Flush Neighot Page,提升性能)
当某个脏页刷回磁盘时,会同时检查该页所在区的所有页,如果亦是脏页,则一同刷回磁盘,这种做法的好处是利用了 AIO 的合并 IO 的特性,提升了性能